

Les applications seront bientôt confrontées à la même mort que les médias imprimés, alors que les Agents d'IA construisent des logiciels personnalisés et vérifiés
Les agents d'IA pourraient mettre fin à l'ère des applications en transformant les logiciels en systèmes vérifiés construits par les utilisateurs
Les agents d'IA pourraient faire de l'exécution de code écrit par des inconnus l'un de ces comportements que les générations futures auront du mal à comprendre.
Une société peut normaliser un risque pendant des décennies, puis le reclasser comme imprudent une fois qu'une option par défaut plus sûre devient disponible.
Boire avant de conduire, rouler sans ceinture de sécurité, fumer à l'intérieur et installer des binaires arbitraires depuis internet appartiennent tous à la même famille d'angles morts historiques. La caractéristique commune est la permission sociale.
Le comportement persiste lorsque l'alternative est coûteuse, peu pratique ou techniquement indisponible. Une fois que le chemin plus sûr devient bon marché et routinier, l'ancien chemin commence à paraître irrationnel.
 La vérification par les agents d'IA pourrait remplacer les hypothèses de confiance logicielle par des chemins d'exécution attestés, des valeurs par défaut plus sûres et une infrastructure contrôlée par l'utilisateur.
La vérification par les agents d'IA pourrait remplacer les hypothèses de confiance logicielle par des chemins d'exécution attestés, des valeurs par défaut plus sûres et une infrastructure contrôlée par l'utilisateur.
Les agents d'IA exposent la faiblesse du modèle de confiance logicielle
Les logiciels modernes reposent encore sur un accord que nous inspectons rarement. Un développeur, une entreprise, une fondation ou un mainteneur anonyme écrit du code. Un canal de distribution le conditionne. Un utilisateur, une entreprise ou un système d'exploitation l'exécute.
La sécurité devient alors une tentative en couches pour gérer les conséquences de cette décision.
Les permissions, la signature de code, les boutiques d'applications, la détection des points de terminaison, le sandboxing, la diligence raisonnable des fournisseurs et la réponse aux incidents existent tous parce que l'acte fondamental reste dangereux : exécuter les instructions de quelqu'un d'autre sur votre machine, dans votre compte, avec accès à vos données.
Ce modèle de confiance a échoué à l'échelle institutionnelle. La compromission de SolarWinds a montré comment du code malveillant inséré dans un processus de construction de logiciels de confiance pouvait être distribué via des mises à jour normales et atteindre des agences gouvernementales, des entreprises technologiques, des réseaux de télécommunications et d'autres cibles dans plusieurs régions.
La leçon opérationnelle était structurelle, et la surface d'attaque était la légitimité même du fournisseur.
Une fois le processus de construction compromis, les marques normales de confiance sont devenues l'infrastructure de livraison de l'attaque.
Le même schéma est apparu dans la porte dérobée XZ Utils, où la CISA a averti en mars 2024 que du code malveillant avait été intégré dans les versions 5.6.0 et 5.6.1 d'une bibliothèque de compression présente dans les distributions Linux.
La National Vulnerability Database a ensuite décrit comment un fichier de test déguisé et une manipulation du processus de construction ont produit une bibliothèque liblzma modifiée capable d'intercepter et de modifier les interactions de données dans les logiciels liés.
Une chaîne d'approvisionnement logicielle peut être compromise bien en amont de l'utilisateur, puis arriver par des canaux qui semblent routiniers. Nous l'avons vu dans la crypto d'innombrables fois avec les exploits DNS et JavaScript npm.
La réponse du secteur a été d'ajouter un processus plus robuste. Le NIST Secure Software Development Framework fournit aux organisations un ensemble commun de pratiques pour construire et acquérir des logiciels avec un risque réduit.
Le framework SLSA intègre la provenance, l'intégrité et la résistance aux altérations dans le pipeline d'artefacts. Ces contrôles sont nécessaires.
Ils révèlent également la limite du modèle actuel. Les entreprises continuent d'affiner les méthodes pour décider quel code externe mérite la confiance.
Le prochain modèle réduit la quantité de code externe qui a besoin de confiance.
Ce changement modifie la signification sociale des logiciels. Aujourd'hui, le code tiers est traité comme un actif de productivité avec une charge sécuritaire.
Demain, il pourrait être traité comme un passif qui nécessite une justification. La question par défaut de l'utilisateur passe de « Quelle application devrais-je installer ? » à « Pourquoi devrais-je exécuter l'application de quelqu'un d'autre quand mon agent peut construire la fonction pour moi ? »
C'est une véritable ligne de fracture. Le logiciel cesse d'être principalement un produit sélectionné sur un marché et devient un résultat généré à la demande dans un environnement d'exécution contrôlé par l'utilisateur.
Les logiciels construits par des agents transforment les applications en expressions jetables d'intention
La direction du mouvement est visible dans les agents de codage. OpenAI Codex a été présenté comme un agent d'ingénierie logicielle basé sur le cloud capable de travailler sur plusieurs tâches en parallèle.
Claude Code d'Anthropic est un système de codage agentique qui cartographie une base de code, modifie des fichiers, exécute des tests et livre du code validé.
L'agent de codage Copilot de GitHub a transposé le même schéma dans le flux de travail GitHub, avec un travail asynchrone sur les problèmes et les pull requests.
Google Jules présente une direction similaire : un agent de codage autonome qui absorbe le contexte du produit, génère des solutions et soumet des pull requests.
Ces produits sont encore présentés comme des outils de développement. Ce cadrage se réduira avec le temps. Pour Codex, c'est déjà le cas. OpenAI a introduit le mois dernier une option d'interface utilisateur axée sur les « chats » et les résultats plutôt que sur le code et les terminaux.
Le changement plus important est que la création de logiciels devient un acte personnel de délégation. Un utilisateur décrit un flux de travail. L'agent génère l'interface, la logique, les intégrations, les tests et le chemin d'exécution.
L'artefact peut durer une heure, une semaine ou un an. Il peut être régénéré, forké, contraint, audité, supprimé ou reconstruit pour un nouveau contexte.
L'application ressemble moins à un objet permanent et plus à une politique locale compilée en une interface utilisable.
Cela a des implications immédiates pour la confiance. Un utilisateur peut toujours observer les applications d'autres personnes. Il peut inspecter les flux de travail, les modèles d'interface, les schémas de données, les prompts, les automatisations et les intégrations de services. Pourtant, l'observation peut rester séparée de l'exécution.
L'utilisateur peut copier l'idée, puis demander à un agent personnel de reconstruire la fonction à partir de premiers principes dans un environnement régi par les propres règles de cet utilisateur. La valeur migre de l'artefact compilé vers le modèle.
La distribution devient moins une question d'expédition de code exécutable et davantage une question de publication d'intentions, de conceptions, de preuves, de schémas et d'attentes API.
La crypto entre dans l'argument par la vérification plutôt que par le branding. L'agent de l'utilisateur se connectera toujours à des services externes.
Il peut appeler des rails de paiement, des systèmes d'identité, des points de terminaison de données de marché, des couches de stockage, des fournisseurs de modèles d'IA, des marchés de calcul, des systèmes de messagerie et des services de conformité. La frontière de confiance se déplace vers ces points de terminaison et les affirmations faites à leur sujet.
Les utilisateurs auront besoin de moyens pour classer les services externes selon l'auditabilité, la provenance, la posture de sécurité et l'alignement économique. Un service construit dans un environnement vérifiable sera évalué différemment d'un point de terminaison opaque contrôlé par une plateforme d'entreprise.
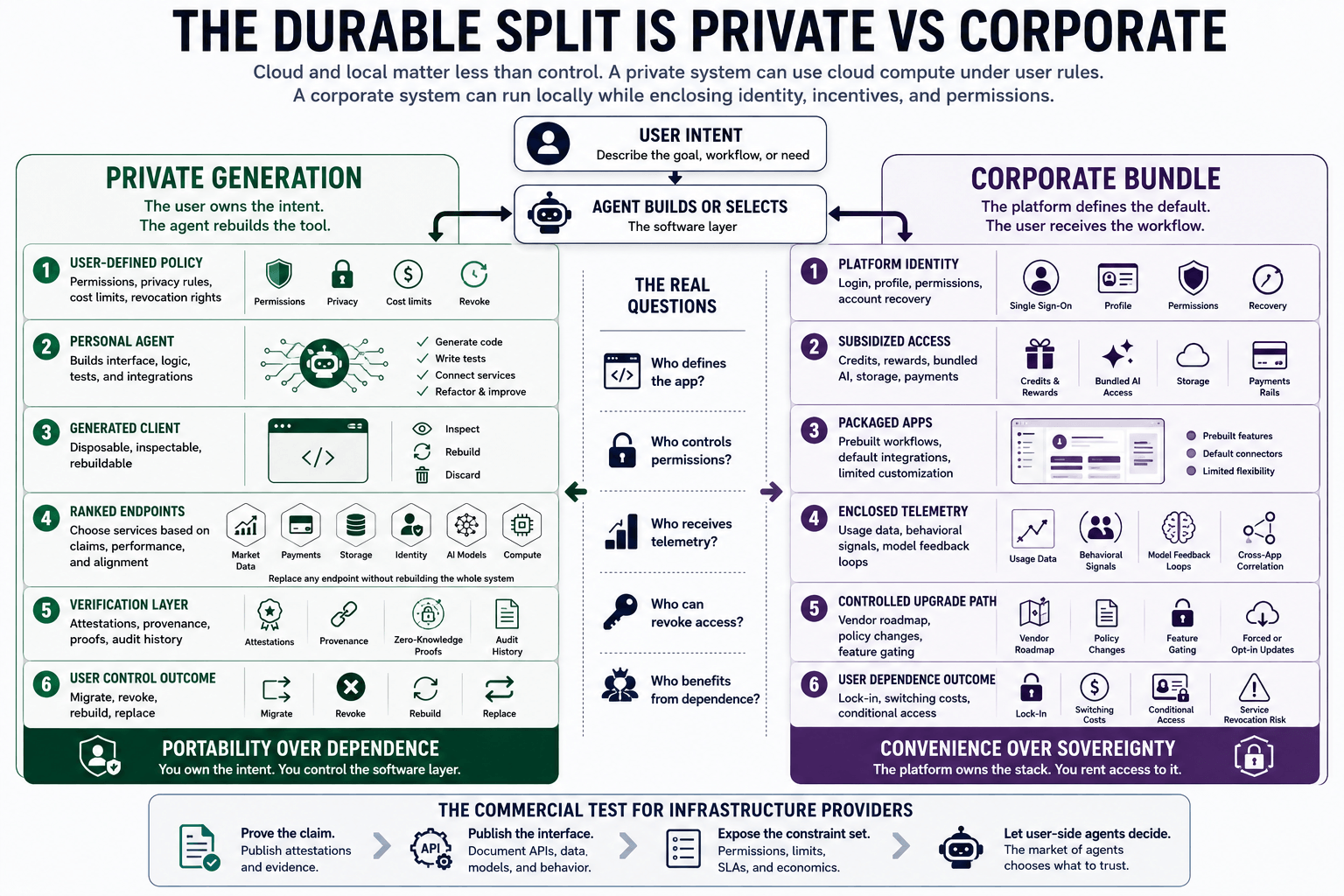 Diagramme comparant les agents d'IA privés appartenant aux utilisateurs avec les plateformes d'IA d'entreprise dans l'infrastructure logicielle.
Diagramme comparant les agents d'IA privés appartenant aux utilisateurs avec les plateformes d'IA d'entreprise dans l'infrastructure logicielle.
Les points de terminaison vérifiables deviennent la nouvelle couche de distribution logicielle
Les systèmes à divulgation nulle de connaissance offrent un chemin vers cette couche de classement. Les ZK-rollups montrent comment le calcul peut être exécuté off-chain tandis qu'une preuve succincte vérifie la validité de la transition d'état résultante on-chain.
Le même schéma conceptuel peut s'étendre au-delà de la mise à l'échelle des transactions. Les utilisateurs peuvent vouloir des preuves qu'un point de terminaison a exécuté du code approuvé, traité des données sous des contraintes définies, préservé des limites de confidentialité, ou produit un résultat à partir d'une construction auditée spécifique.
La preuve peut préserver la confidentialité interne tout en réduisant l'écart de confiance entre un agent personnel et une dépendance externe.
L'interface à long terme pourrait ressembler à une couche opérationnelle contrôlée par un agent. L'utilisateur demande un tableau de bord, un outil de portefeuille, un assistant de recherche, un système de publication, un CRM personnel, un flux de travail comptable ou un moniteur de sécurité.
L'agent l'assemble à partir de code généré et de points de terminaison classés. Le code est inspectable parce que l'agent l'a créé.
Les dépendances sont contraintes parce que l'agent les a sélectionnées selon une politique. L'environnement d'exécution est auditable parce que l'utilisateur l'a choisi comme exigence.
L'utilisateur participe toujours à une économie en réseau. Le contrôle se rapproche de l'individu.
L'aboutissement de cette transition est un marché de fonctions vérifiables, de clients générés par des agents et de services externes classés. Les développeurs tiers existent toujours, mais leur rôle change.
Ils publient des protocoles, des API, des modèles, des preuves, des modèles d'IA, des composants et des implémentations de référence. Les utilisateurs exécutent leurs propres versions.
Les entreprises existent toujours, mais leur avantage passe du contrôle de la distribution à la preuve de fiabilité. Les communautés open source existent toujours, mais le fardeau passe de demander aux utilisateurs de faire confiance aux mainteneurs à donner aux agents suffisamment de matériel structuré pour reconstruire en toute sécurité.
L'ancienne économie logicielle vendait des applications finies. La nouvelle vend des capacités crédibles.
Un tracker de portefeuille devient une interface générée sur des points de terminaison de données de marché, des permissions de portefeuille, une logique fiscale et des règles de reporting. Un système de publication devient un flux de travail généré sur l'identité, l'édition, la gestion de contenu, l'analytique et les API de distribution.
Un terminal de recherche devient une surface générée à partir de bases de données, d'appels de modèles, de vérifications de provenance et de notes privées. Dans chaque cas, l'agent de l'utilisateur gère la composition.
Le monde externe fournit des ressources vérifiables. Ce changement crée également un test commercial pour chaque fournisseur d'infrastructure : prouver l'affirmation, publier l'interface, exposer l'ensemble des contraintes et laisser les agents côté utilisateur décider si le service mérite d'être inclus.
La division centrale devient la souveraineté logicielle privée versus la commodité gérée
Le débat habituel cadre l'avenir comme local versus cloud. Cette division capture une partie de la question d'infrastructure, tout en manquant l'économie politique.
Un système privé peut utiliser le calcul cloud sous des contraintes définies par l'utilisateur. Un système d'entreprise peut fonctionner localement tout en enfermant l'identité, les incitations, les permissions et la monétisation dans une pile contrôlée par le fournisseur.
La division la plus durable est privé versus entreprise. Qui définit l'application ?
Qui décide de ce à quoi elle peut accéder ? Qui reçoit la télémétrie ?
Qui définit le chemin de mise à niveau ? Qui peut révoquer la fonction ?
Qui bénéficie de la dépendance de l'utilisateur ?
Cette division deviendra plus visible à mesure que les logiciels agentiques deviennent suffisamment bon marché pour les utilisateurs ordinaires. Un chemin mène vers la souveraineté logicielle personnelle.
Les utilisateurs maintiennent des agents qui construisent et reconstruisent les outils dont ils ont besoin. Ils choisissent des fournisseurs de points de terminaison en fonction des attestations, du coût, de la fiabilité, de la confidentialité et de l'alignement.
Ils peuvent abandonner une interface tout en préservant le flux de travail sous-jacent. Ils peuvent migrer d'un point de terminaison à un autre.
Ils peuvent générer un nouveau client lorsqu'un ancien devient compromis, capturé ou inefficace. La couche logicielle devient portable parce que l'utilisateur possède l'intention, et l'agent peut reproduire l'implémentation.
L'autre chemin mène vers la commodité gérée. Les plateformes d'entreprise offriront des applications subventionnées, une identité intégrée, des crédits, des paiements, du stockage, un accès à l'IA et des flux de travail par défaut.
Une partie de cela sera utile. Une partie sera économiquement coercitive.
Si l'abondance piloté par l'IA produit des régimes de revenus publics ou privés proches du RUB, des crédits de calcul, des distributions de tokens ou des avantages liés aux plateformes, le rail de distribution pourrait devenir un mécanisme de verrouillage doux. Les utilisateurs peuvent recevoir l'accès aux services via un écosystème qui définit également quels logiciels ils exécutent, comment leurs données se déplacent et quels agents peuvent agir en leur nom.
La couche RUB est la version la plus sensible de ce problème. Sam Altman a longtemps été associé aux débats de l'ère de l'IA sur la distribution des revenus, et Worldcoin a été encadré, en partie, autour de la preuve d'humanité et de la possibilité de distributions similaires au RUB.
Le point plus large est plus grand qu'un seul projet. Lorsque le soutien économique, la vérification d'identité, l'accès au calcul et les permissions logicielles convergent, la participation peut devenir conditionnelle tout en paraissant volontaire.
Un utilisateur peut être libre de se retirer en théorie tout en étant poussé vers une couche d'application gérée en pratique.
La commodité devient le principal champ de bataille. La pile d'entreprise gagnera des utilisateurs grâce à une faible friction.
Elle offrira des valeurs par défaut soignées, un accès instantané, une IA intégrée, une compatibilité sociale, des flux de récupération, une couverture de conformité et des récompenses. La pile privée devra concurrencer sur quelque chose de plus difficile : une autonomie qui se sent utilisable.
Elle doit donner aux utilisateurs une raison d'accepter plus de responsabilités tout en évitant l'administration technique. L'agent personnel devient décisif parce qu'il peut absorber la complexité qui rendait auparavant la souveraineté impraticable.
Le prochain test est de savoir si les utilisateurs choisissent la confiance générée plutôt que la commodité packagée
Le risque de premier ordre est que les utilisateurs échangent le contrôle contre la commodité avant de comprendre le coût. Le risque de second ordre est que l'échange devienne subventionné, normalisé et finalement requis pour l'accès à la vie économique.
Les applications d'entreprise peuvent devenir l'environnement par défaut pour ceux qui acceptent les avantages groupés. Les applications générées de manière privée peuvent devenir la valeur par défaut pour ceux qui sont prêts à payer, vérifier, configurer ou auto-conserver leur couche logicielle.
Cela crée une nouvelle fracture de classe autour du contrôle d'exécution. La question est de savoir si l'IA agentique compresse cette fracture ou l'approfondit.
Cette transition sera inégale. Les secteurs réglementés évolueront plus lentement.
Les entreprises défendront les écosystèmes d'applications avec des arguments de conformité. Les consommateurs continueront à choisir la commodité par défaut lorsque l'alternative privée semble fragile.
Les attaquants cibleront les agents, les prompts, la sélection des dépendances, les chaînes d'approvisionnement des modèles et les attestations des points de terminaison. Les systèmes de vérification créeront de nouveaux goulots d'étranglement s'ils sont capturés par un petit nombre d'autorités de certification, de plateformes cloud ou de fournisseurs de modèles.
La souveraineté logicielle personnelle peut devenir une autre affirmation de marque à moins que les utilisateurs puissent inspecter, migrer et révoquer.
Pourtant, la direction est suffisamment claire pour définir le prochain test. La question est de savoir si les gens accepteront la commodité plutôt que la souveraineté une fois que leurs propres agents pourront construire la plupart de ce dont ils ont besoin.
Aujourd'hui, la réponse est largement oui parce que l'alternative reste trop exigeante. Demain, la réponse devient moins certaine.
Un utilisateur qui peut générer une application fonctionnelle, contraindre ses permissions, auditer ses dépendances, se connecter uniquement à des points de terminaison classés et la reconstruire lorsque les conditions changent dispose d'une véritable alternative au bundle logiciel d'entreprise.
Cette alternative semblera étrange au début. Puis elle semblera prudente.
Puis elle pourrait devenir l'attente par défaut pour quiconque gère de l'argent, une identité, des données de santé, des communications privées, de la recherche ou des opérations commerciales. L'exécution de code tiers opaque survivra lorsque la commodité dominera, lorsque les subventions fausseront les choix et lorsque les utilisateurs accepteront des environnements gérés en échange d'un accès économique.
Elle s'estompera là où les agents rendent la génération privée routinière.
La reclassification sociale se produira lentement, puis soudainement. L'ancienne habitude restera familière jusqu'à ce que la nouvelle valeur par défaut devienne évidente.
Une fois que les utilisateurs pourront demander à leurs propres agents de construire l'application, de vérifier le chemin d'exécution et de se connecter uniquement à des points de terminaison attestés, le fardeau de l'explication s'inverse. La personne qui exécute le code de quelqu'un d'autre aura besoin d'une raison.
La personne qui construit via un agent utilisera simplement la valeur par défaut plus sûre. Cependant, elle devra peut-être aussi accepter de manquer les incitations d'entreprise accordées à ceux qui restent connectés à la matrice.
L'article Les applications feront bientôt face à la même mort que les médias imprimés alors que les agents d'IA construisent des logiciels personnalisés et vérifiés est apparu en premier sur CryptoSlate.


Vous aimerez peut-être aussi

Semaine Crypto Chaude : 6 Événements Qui Pourraient Faire Bouger les Marchés (18–23 Mai 2026)

Le mouvement de dette de Strategy augmente les chances de vente de Bitcoin et met à l'épreuve le récit central de Saylor




