

La dernière recherche de DGrid AI s'attaque à une faille fondamentale dans le scoring décentralisé de l'IA
DGrid AI présente un nouveau cadre Proof of Quality conçu pour évaluer les résultats de l'IA et améliorer la distribution des récompenses au sein des réseaux décentralisés.
- La nouvelle recherche PoQ de DGrid AI introduit un scoring sans référence pour récompenser les nœuds d'IA sans avoir besoin de réponses correctes.
- DGrid a entraîné des juges d'IA spécialisés pour évaluer la qualité des résultats, améliorant ainsi les systèmes de récompenses des Agents d'IA décentralisés à grande échelle.
- Les nouveaux modèles Proof of Quality de DGrid AI aident les réseaux d'IA décentralisés à évaluer les réponses avec précision sans données de vérité terrain.
Les réseaux d'IA décentralisés ont un problème de paiement sur lequel les chercheurs travaillent discrètement depuis des années, et un récent article de DGrid AI pose directement la question sur la table. Les systèmes de scoring de qualité alimentant les récompenses des nœuds ont largement dépendu de la disponibilité de la bonne réponse pour effectuer une comparaison. En production, cette réponse existe rarement.
Cet article, le quatrième de la série de recherches en cours de DGrid sur le Proof of Quality (PoQ), propose une alternative entraînée et publie les chiffres qui la sous-tendent. Le PoQ utilise de petits modèles évaluateurs pour scorer la qualité de chaque résultat, et ces scores pilotent les récompenses. Économique, et ça passe à l'échelle.
DGrid a construit cela brique par brique : une version tenant compte des coûts qui intègre la latence dans le calcul des paiements, une couche de robustesse adversariale qui tient bon quand les scoreurs mentent ou sont paresseux, et un cadre qui décompose la « qualité » en parties inspectables. Une ingénierie solide. Et chaque couche continuait à se heurter au même mur.
Comment le problème de scoring s'est développé
La structure de base d'un réseau d'inférence décentralisé crée un défi de mesure. Des nœuds indépendants exécutent des modèles de langage et répondent aux requêtes des utilisateurs. Ces réponses doivent être scorées car les scores déterminent la rémunération. La vérification cryptographique de chaque calcul serait techniquement irréprochable mais prohibitivement coûteuse à grande échelle, donc la voie pratique a été l'évaluation automatisée de la qualité à l'aide de modèles plus petits.
Les travaux antérieurs de DGrid ont développé cette approche de manière incrémentale, en ajoutant des paiements ajustés à la latence, des défenses contre les scoreurs manipulateurs, et une décomposition plus granulaire de ce que « qualité » signifie réellement dans un contexte de scoring. Ce qu'il ne pouvait pas entièrement résoudre, c'était le signal d'évaluation lui-même.
Le signal le plus fort dont disposait l'équipe était la similarité sémantique : comparer le résultat du modèle à une réponse correcte connue et mesurer la distance entre elles dans l'espace d'embedding. Cela fonctionne dans des environnements de benchmark où des réponses de référence existent. Cela ne fonctionne pas dans un réseau en direct où les utilisateurs posent des questions ouvertes et où aucune vérité terrain n'attend dans une base de données.
Les alternatives prêtes à l'emploi ont obtenu de moins bons résultats. Un cross-encodeur NLI, une classe de modèles conçue pour évaluer l'implication logique entre phrases, a retourné une corrélation de Pearson de −0,363 lorsqu'il était utilisé pour noter la qualité des réponses sans réponse de référence. Une corrélation négative signifie que le modèle était plus susceptible de favoriser les mauvaises réponses par rapport aux bonnes. Ce n'est pas un outil d'évaluation utilisable.
Ce que l'article propose
Plutôt que d'adapter des modèles existants, les chercheurs ont entraîné trois juges spécifiquement pour le scoring de qualité sans référence. Chacun prend une question et une réponse en entrée et produit un score de 0 à 10, sans réponse correcte fournie.
Les trois modèles diffèrent principalement par leur taille et leur vitesse :
- TextCNN (~10M paramètres) s'exécute en environ 1 milliseconde par appel, ce qui le rend adapté au filtrage de premier passage à haut débit.
- MiniLM (22M paramètres) se situe au milieu avec environ 13 millisecondes.
- DeBERTa (184M paramètres) prend environ 15 millisecondes et est optimisé pour la précision.
L'entraînement a suivi un processus en deux étapes. Les modèles ont d'abord été pré-entraînés sur UltraFeedback, un ensemble de données public de réponses notées par GPT-4, avant un affinage sur la distribution de tâches propre au réseau. L'intention était de donner aux juges une compréhension de base large de la qualité avant de restreindre leur focus au contexte de scoring spécifique.
Le résultat principal
Sur un ensemble de test de 300 exemples mis de côté, le juge DeBERTa a atteint une corrélation de Pearson de 0,747 par rapport au proxy de vérité terrain — sans accès à aucune réponse de référence. Les évaluateurs basés sur des références du cadre précédent, qui avaient accès aux réponses correctes, ont atteint un maximum de 0,647.
L'écart a une explication simple. Les anciens évaluateurs étaient des métriques de similarité mesurant la distance cosinus par rapport à un embedding de référence. Les nouveaux juges ont été optimisés de bout en bout pour la tâche de scoring elle-même. La différence de performance reflète cette distinction plus que toute avancée architecturale.
Une mise en garde que les auteurs incluent : la vérité terrain utilisée ici est elle-même un proxy — le chevauchement de mots au niveau des tokens plutôt que le jugement humain. Les juges corrèlent bien avec cette métrique, mais la question de savoir si le chevauchement de mots reflète de manière fiable ce qu'un humain considérerait comme une réponse de qualité reste une question distincte et non résolue.
Deux fonctionnalités orientées déploiement accompagnent les juges. Un pipeline en cascade achemine d'abord les requêtes via le modèle léger et n'escalade vers des modèles plus lourds que lorsque les scores sont ambigus, réduisant les coûts d'évaluation jusqu'à 72,7 % au paramètre de seuil le plus agressif, bien que la corrélation tombe à environ 0,51 dans cette configuration. Un mécanisme de calibration en ligne, fonctionnant sans réglage manuel, identifie systématiquement la qualité sémantique comme le signal dominant et ajuste les poids en conséquence, lui attribuant 4,7 fois son poids initial au fil du temps.
Où le système peine encore
Les juges se comportent de manière inégale selon les types de tâches. Sur les questions-réponses, la corrélation atteint 0,830. Sur la synthèse, elle tombe à 0,199. L'article attribue cela non pas à un échec des juges eux-mêmes, mais à la métrique d'évaluation utilisée lors de l'entraînement : le chevauchement brut de mots est une mauvaise mesure de la qualité de synthèse, donc les modèles entraînés contre elle apprennent à suivre un signal faible. Les auteurs décrivent cela comme le principal problème ouvert plutôt qu'une limitation connue gérée discrètement.
Ce cadrage est cohérent avec la manière dont l'article présente ses résultats dans l'ensemble — méthodiquement, avec les cas d'échec aussi clairement énoncés que les améliorations. Quatre articles après le début de ce fil de recherche, le travail ressemble moins à une annonce de produit et davantage à une équipe qui comble progressivement les lacunes de quelque chose qu'elle a l'intention de déployer réellement.
Avertissement : Ce contenu est fourni par un tiers. Ni crypto.news ni l'auteur de cet article n'approuve aucun produit mentionné sur cette page. Les utilisateurs doivent effectuer leurs propres recherches avant de prendre toute mesure liée à l'entreprise.


Vous aimerez peut-être aussi
Mise à jour des Tokenomics d'Aster : Rachat et combustion de 99% des frais désormais en direct
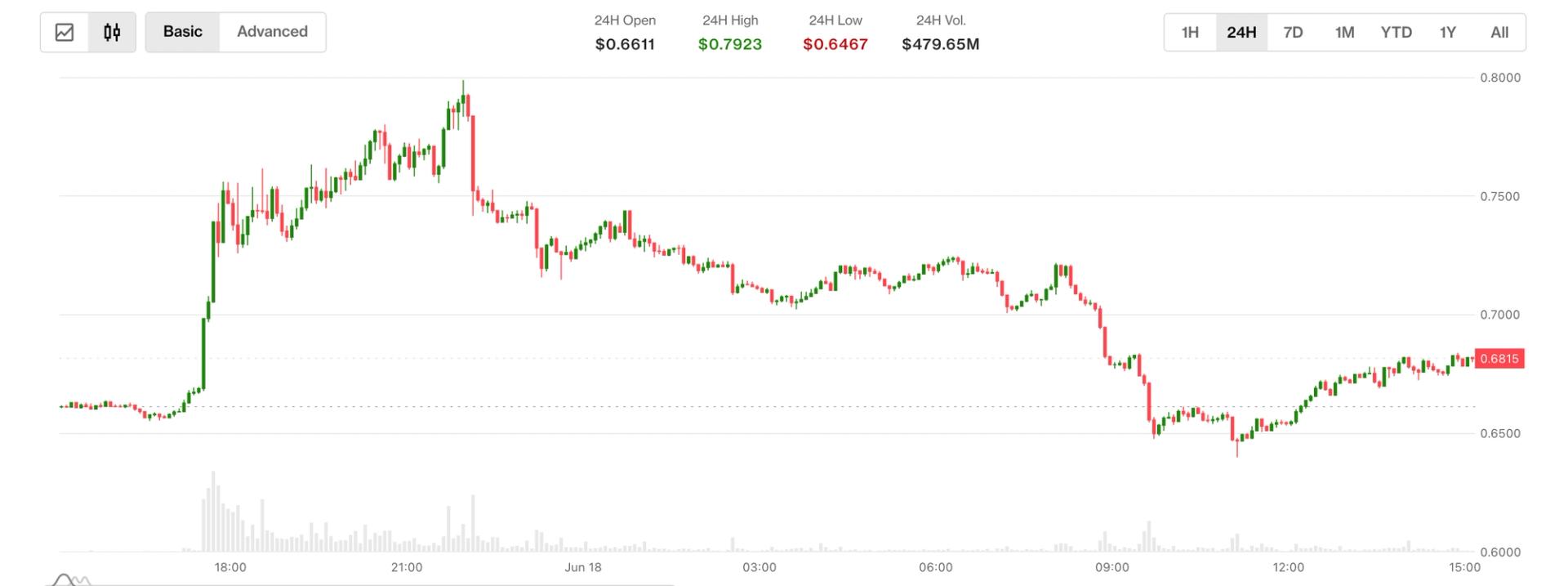
Aster a bondi de plus de 10% grâce à une mise à niveau radicale de « rachat et combustion ». Mais les gains ont été de courte durée

Les tensions sur les marchés de l'énergie sont une source de préoccupation pour la stabilité financière



