

3D セグメンテーションの最大のボトルネックを解決する
:::info 著者:
(1) George Tang、マサチューセッツ工科大学;
(2) Krishna Murthy Jatavallabhula、マサチューセッツ工科大学;
(3) Antonio Torralba、マサチューセッツ工科大学.
:::
リンク一覧
要約とI. はじめに
II. 背景
III. 手法
IV. 実験
V. 結論と参考文献
\ 
\ 要約— 我々は、ポーズ付きRGB画像のシーケンスから3Dインスタンスセグメンテーションのための暗黙的シーン表現を学習する問題に取り組みます。これに向けて、新しい視点から描画してビュー整合インスタンスセグメンテーションマスクを生成できるラベルフィールドを効率的に学習する新しいフレームワーク3DIMILを紹介します。3DIMILは既存の暗黙的シーン表現ベースの手法のトレーニングと推論の実行時間を大幅に改善します。複雑なトレーニング手順と損失関数設計を必要とする自己教師あり方式でニューラルフィールドを最適化する従来技術とは対照的に、3DIMILは2段階のプロセスを活用します。第一段階のInstanceMapは、フロントエンドインスタンスセグメンテーションモデルによって生成された画像シーケンスの2Dセグメンテーションマスクを入力とし、画像間の対応するマスクを3Dラベルに関連付けます。これらのほぼビュー整合した疑似ラベルマスクは、第二段階のInstanceLiftで使用され、InstanceMapで見逃された領域を補間し、曖昧さを解決するニューラルラベルフィールドのトレーニングを監督します。さらに、トレーニング済みラベルフィールドと既製の画像セグメンテーションモデルが与えられた場合に、両方の出力を融合することでインスタンスマスクのほぼリアルタイムのローカライゼーションを可能にするInstanceLocを導入します。ReplicaとScanNetデータセットのシーケンスで3DIMILを評価し、画像シーケンスに対する穏やかな仮定の下での3DIMILの有効性を実証します。同等の品質で既存の暗黙的シーン表現手法に対して大幅な実用的な高速化を達成し、より高速で効果的な3Dシーン理解を促進する可能性を示しています。
I. はじめに
知的エージェントは、ナビゲーションや操作などのコンテキスト固有のアクションを効果的に実行するために、オブジェクトレベルでのシーン理解を必要とします。インターネットスケールのデータセットでトレーニングされたスケーラブルなモデルにより、画像からオブジェクトをセグメント化する技術は目覚ましい進歩を遂げていますが[1]、[2]、そのような能力を3D設定に拡張することは依然として課題です。
\ 本研究では、基礎となるシーンを構成オブジェクトのセットに分解するポーズ付き2D画像から3Dシーン表現を学習する問題に取り組みます。この問題に対する既存のアプローチは、クラス非依存の3Dセグメンテーションモデル[3]、[4]のトレーニングに焦点を当て、大量のアノテーション付き3Dデータを必要とし、明示的な3Dシーン表現(例:ポイントクラウド)上で直接操作します。別のアプローチクラス[5]、[6]は、代わりに既製のインスタンスセグメンテーションモデルからセグメンテーションマスクを直接、ニューラルラディアンスフィールド(NeRF)[7]などの暗黙的3D表現に持ち上げることを提案し、新しい視点から3D整合インスタンスマスクをレンダリングできるようにしています。
\ しかし、ニューラルフィールドベースのアプローチは最適化が非常に困難であることで知られており、[5]と[6]は低〜中解像度の画像(例:300 × 640)の最適化に数時間を要します。特に、Panoptic Lifting [5]はシーン内のオブジェクト数に対して立方体的にスケールするため、数百のオブジェクトを持つシーンには適用できず、一方でContrastively Lifting [6]は複雑な多段階トレーニング手順を必要とし、ロボティクスアプリケーションでの実用性を妨げています。
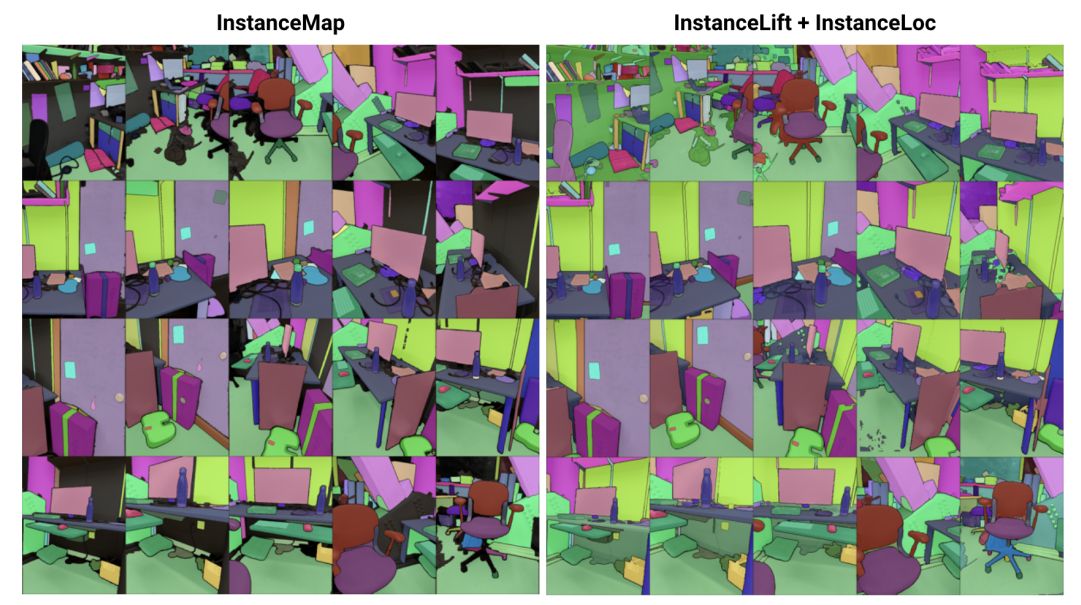
\ そこで我々は、ポーズ付きRGB画像から3D整合インスタンスセグメンテーションを効率的に学習する技術である3DIMLを提案します。3DIMILはInstanceMapとInstanceLiftの2つのフェーズで構成されています。フロントエンドインスタンスセグメンテーションモデル[2]を使用してRGBシーケンスから抽出されたビュー不整合2Dインスタンスマスクが与えられると、InstanceMapはビュー整合インスタンスマスクのシーケンスを生成します。そのために、まず類似した画像ペア間のキーポイントマッチを使用してフレーム間でマスクを関連付けます。次に、これらの潜在的にノイズのある関連付けを使用して、ニューラルラベルフィールドであるInstanceLiftを監督し、3D構造を活用してInstanceMapで見逃されたラベルを補間し、曖昧さを解決します。マルチステージトレーニングと追加の損失関数エンジニアリングを必要とする先行研究とは異なり、インスタンスラベル監督のために単一のレンダリング損失を使用し、トレーニングプロセスが大幅に速く収束できるようにします。InstanceMapを含む3DIMLの総実行時間は10〜20分であり、先行技術の3〜6時間と比較して大幅に短縮されています。
\ さらに、トレーニング済みラベルフィールドと既製の画像セグメンテーションモデルが与えられた場合に、ラベルフィールドにスパースにクエリを実行し、ラベル予測と抽出された画像領域を融合することで、その画像でセグメント化されたすべてのインスタンスをローカライズする高速なローカライゼーションパイプラインであるInstaLocを考案しました。最後に、3DIMLは非常にモジュラーであり、より高性能なものが利用可能になると、我々の手法のコンポーネントを簡単に交換できます。
\ 要約すると、我々の貢献は以下の通りです:
\ • 3Dシーンを構成オブジェクトに分解する効率的なニューラルフィールド学習アプローチ
\ • トレーニング済みラベルフィールドへのスパースクエリと高性能な画像インスタンスセグメンテーションモデルを融合して3D整合インスタンスセグメンテーションマスクを生成する高速インスタンスローカライゼーションアルゴリズム
\ • 単一GPU(NVIDIA RTX 3090)でベンチマークされた先行技術に対する14〜24倍の全体的な実用的な実行時間の改善
II. 背景
2Dセグメンテーション: ビジョントランスフォーマーアーキテクチャの普及と画像データセットの規模の拡大により、一連の最先端画像セグメンテーションモデルが生まれました。PanopticとContrastive Liftingは両方とも、Mask2Former [1]によって生成されたパノプティックセグメンテーションマスクをニューラルフィールドを学習することで3Dに持ち上げます。オープンセットセグメンテーションに向けて、segment anything(SAM)[2]は11百万画像の10億マスクでトレーニングすることで前例のないパフォーマンスを達成しています。HQ-SAM [9]は細粒度マスクのためにSAMを改良しています。FastSAM [8]はSAMをCNNアーキテクチャに蒸留し、桁違いに高速でありながら同様のパフォーマンスを達成しています。本研究では、パーツレベルではなくオブジェクトレベルのセグメンテーションマスクを生成するためにSAMを洗練したGroundedSAM [10]、[11]を使用しています。
\ 3Dインスタンスセグメンテーションのためのニューラルフィールド:NeRFは複雑な幾何学、セマンティクス、その他のモダリティを正確にエンコードし、視点不整合監督を解決できる暗黙的シーン表現です[12]。Panoptic lifting [5]はNeRFの効率的なバリアントであるTensoRF [13]上にセマンティクスとインスタンスのブランチを構築し、参照ビュー不整合マスクが与えられた場合に学習したインスタンスマスクを代理オブジェクトIDに割り当てるためにハンガリアンマッチング損失関数を利用します。これはオブジェクト数の増加に対して立方体的にスケールが悪く(ハンガリアンマッチングの立方体複雑性による)、数百のオブジェクトを持つシーンには適用できません。Contrastive lifting [6]はこれに対処するため、代わりにシーン特徴に対する対照学習を採用し、同じマスクに投影されるかどうかによって正と負の関係を決定します。さらに、contrastive liftingは安定したトレーニングのために遅速クラスタリングベースの損失を必要とし、panoptic liftingよりも高速なパフォーマンスをもたらしますが、複数段階のトレーニングが必要で、収束が遅くなります。我々と同時に、Instance-NeRF [14]は直接ラベルフィールドを学習しますが、彼らはNeRF-RPN [15]を利用してNeRF内のオブジェクトを検出することにマスク関連付けを基づかせています。対照的に、我々のアプローチは非常に高い画像解像度へのスケーリングを可能にしながら、セグメンテーションマスクをレンダリングするために少数(40〜60)のニューラルフィールドクエリのみを必要とします。
\ Structure from Motion:InstanceMapでのマスク関連付け中に、hLoc [16]などのスケーラブルな3D再構成パイプラインからインスピレーションを得ており、まず画像視点をマッチングするための視覚的記述子の使用、次にマスク関連付けの前提としてキーポイントマッチングの適用を含みます。キーポイントの抽出とマッチングにはLoFTR [17]を利用しています。
\
:::info この論文はarxivで入手可能であり、CC by 4.0 Deed(Attribution 4.0 International)ライセンスの下で公開されています。
:::
\
関連コンテンツ

パニック売りがイーサリアムを襲う:ETH移動量が昨年8月以来のピークレベルに到達

制御不能の政策が「トランプのカトリーナ」を生み出し、MAGAを粉砕:分析
