

How Dockerized Android Performs Across Different Operating Systems
:::info Authors:
(1) Daniele Capone, SecSI srl, Napoli, Italy (daniele.capone@secsi.io);
(2) Francesco Caturano, Dept. of Electrical Engineering and Information, Technology University of Napoli Federico II, Napoli, Italy (francesco.caturano@unina.i)
(3) Angelo Delicato, SecSI srl, Napoli, Italy (angelo.delicato@secsi.io);
(4) Gaetano Perrone, Dept. of Electrical Engineering and Information Technology, University of Napoli Federico II, Napoli, Italy (gaetano.perrone@unina.it)
(5) Simon Pietro Romano, Dept. of Electrical Engineering and Information Technology, University of Napoli Federico II, Napoli, Italy (spromano@unina.it).
:::
Table of Links
Abstract and I. Introduction
II. Related Work
III. Dockerized Android: Design
IV. Dockerized Android Architecture
V. Evaluation
VI. Conclusion and Future Developments, and References
V. EVALUATION
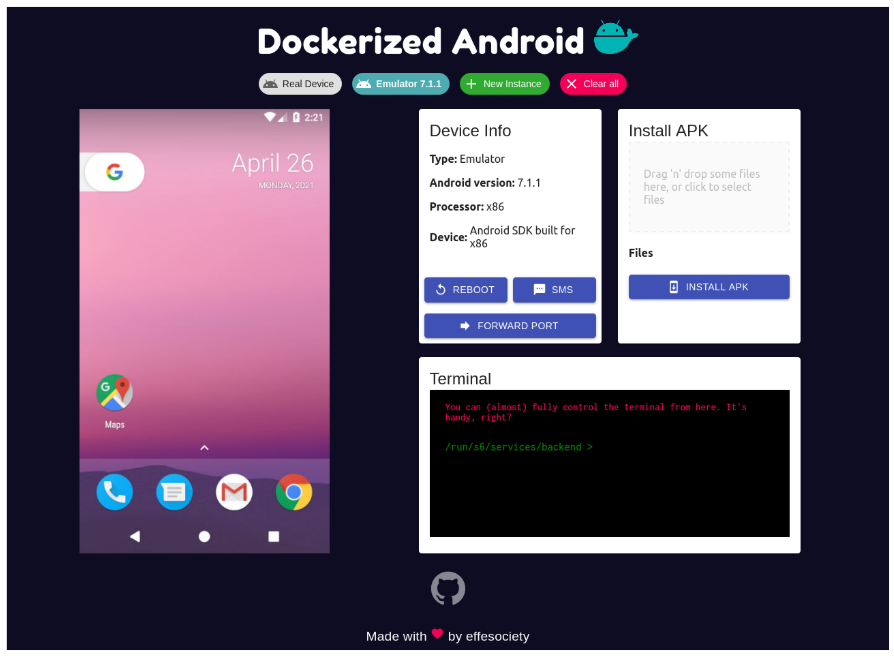
This section assesses the Dockerized Android platform by examining several aspects. Firstly, we emphasize the differences between the Core for Emulator and Core for Real Device components in terms of features and highlight compatibility with the three most used Operating Systems. Then, we provide practical usage examples of Dockerized Android and discuss coverage of the requirements defined in Section III.
\ 
\ A. Differences between Core for Emulator and Core for Real Device
\ Even if a significant effort has been put into creating a system that has the same features for both kinds of devices, there are limitations when emulation is used:
\ • SMS ADB send/reception feature: in emulated devices, it is possible to automate the send and reception of SMS messages through the ADB software. Obviously, this is not natively possible for real devices. Therefore, the user must manually send and receive SMS messages to implement SMS attack scenarios. A solution to address this problem could be the realization of a custom Android application that could be installed on a real device and could be instrumented to send and receive messages automatically.
\ • Networking: networking is quite different between the Emulator and the Real device flavors. In the emulator version, the AVD is created inside the Docker container, and therefore it shares the container’s IP address. Instead, the real device is physically connected to the machine that runs the container and keeps its own IP address.
\ • Hardware virtualization: for the hardware components, the situation is quite different, too: some hardware devices like the GPS and the microphone can be emulated. In particular, the GPS location of the device can be set through ADB, and the microphone of the host machine can be shared with the emulator. There are other hardware components that currently cannot be emulated, like, e.g. Bluetooth.
\ B. Host evaluation for cross-platform compatibility
\ The non-functional requirement NF04 (Cross-platform compatibility) states that the resulting system should be usable from within any host OS. This refers to the OS of the machine that runs the Docker containers. Table III provides a summary of the compatibility with Linux, Windows, and OS X.
\ 
\ The problem with Windows is that currently, the best way to use Docker is through the Windows Subsystem for Linux (WSL) framework. Unfortunately, WSL does not support nested virtualization yet, and this feature is required to run the Android emulator inside a Docker container. However, the feature will be available in upcoming WSL releases. It might be possible to run the Core for Emulator flavor on Windows by using a virtual machine, though losing all of the performance benefits associated with containerization. A similar issue does exist with OS X, with which there is currently no way to run the Core for Emulator. Besides, OS X does not allow sharing the USB device with a Docker container. For this reason, the only ways to use the Core for Real Device flavor are to either run ADB over Wi-Fi or connect to the host ADB from within the Docker container.
\ In the remainder of this section, we show the effectiveness of Dockerized Android in reproducing security kill chains by using both the Core for Emulator and Core for Real Device.
\ C. Security attack reproduction on the emulator
\ We herein focus on a sample vulnerability scenario associated with CVE-2018-7661[1]. This CVE is related to the free version of the application “Wi-Fi Baby Monitor”. This application has to be installed on two devices in order to act as a so-called baby monitor (a radio system used to remotely listen to sounds emitted by an infant). As reported in the National Vulnerability Database, “Wi-Fi Baby Monitor Free & Lite” before version 2.02.2 allows remote attackers to obtain audio data via certain specific requests to TCP port numbers 8258 and 8257”.
\ 
\ The premium version of this application offers users the ability to specify a password to use in the pairing process. By monitoring the network traffic, it is possible to observe that:
\ • the initial connection takes place on port 8257;
\ • the same sequence is always sent to start the pairing process;
\ • at the end of the pairing process, a new connection is started on port 8258. This port is used to transmit the audio data;
\ • after connecting to the port 8258, the other connection on the port 8257 is kept open and used as a heartbeat for the session;
\ • on the heartbeat connection, the client periodically sends the hexadecimal byte 0x01 (about once per second);
\ The proof of concept that allows the attacker to obtain audio data is given in [21]. This Proof of Concept (PoC) is easily reproducible on Dockerized Android through the realization of an infrastructure composed of three services:
\ • core-emulator: an instance of the Core component with a pre-installed Baby Monitor app acting as the sender;
\ • ui: the UI component to control what is going on;
\ • attacker: a customized version of Kali Linux that automatically installs all the dependencies needed for the execution of the PoC.
\ This is also a perfect example to show the Port Forwarding feature used to enable the communications.
\ D. Security attack reproduction on the real device
\ With the real device, we examine a further vulnerability, known as BlueBorne. The term “BlueBorne” refers to multiple security vulnerabilities related to the implementation of Bluetooth. These vulnerabilities were discovered by a group of researchers from Armis Security, an IoT security company, in September 2017. According to Armis, at the time of discovery, around 8.2 billion devices were potentially affected by the BlueBorne attack vector, which affects the Bluetooth implementations in Android, iOS, Microsoft, and Linux, hence impacting almost all Bluetooth device types such as smartphones, laptops, and smartwatches. BlueBorne was analyzed in detail in a paper published on the 12th of September 2017 by Ben Seri and Gregor Vishnepolsk [22]. Eight different vulnerabilities can be used as part of the attack vector.
\ Regarding Android, all devices and versions (therefore versions older than Android Oreo, which was released in December 2017) are affected by the above-mentioned vulnerabilities, except for devices that support BLE (Bluetooth Low Energy). In general, two requirements should be satisfied to exploit the vulnerability: (i) the target device must have Bluetooth enabled; (ii) the attacker must be close enough to the target device. As the Bluetooth feature is not available in the Core Emulator, the kill-chain in question can only be reproduced on real devices.
\ 1) BlueBorne full reproduction on Dockerized Android: In order to show the effectiveness of Dockerized Android, we developed a kill chain that exploits two Remote Code Execution (RCE) vulnerabilities that affect Android, i.e., CVE-2017- 0781 and CVE-2017-0782. These vulnerabilities fall within the Bluetooth set vulnerability’s set defined “BlueBorne” and discovered by a group of security researchers from Armis Security [23].
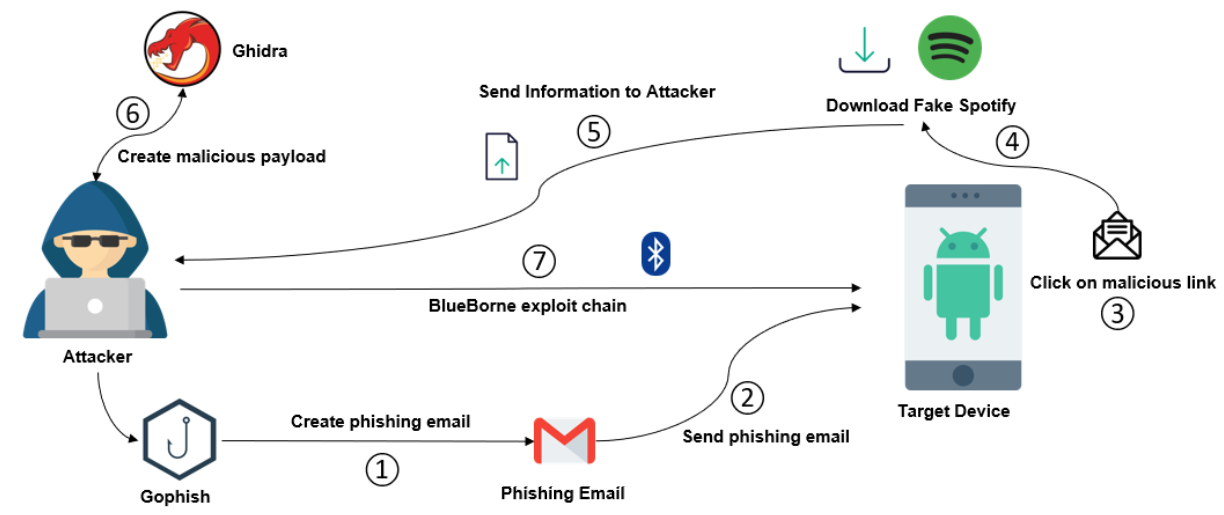
\ The diagram in Fig. 4 gives an overview of the developed kill chain:
\
- The attacker creates a phishing email through Gophish, a phishing generator software.
\ 2) The phishing email is sent to a victim’s mailbox.
\ 3) The victim reads the phishing email and erroneously clicks a malicious link contained in the email’s body.
\ 4) The malicious link allows the attacker to trigger an attack that downloads and installs a fake application on the victim’s mobile device.
\ 5) The malicious information sends relevant mobile information to the attacker. This information is required for the exploitation of the two vulnerabilities.
\ 6) The attacker crafts a malicious payload to exploit the vulnerabilities.
\ 7) The attacker sends the attack by exploiting the Bluetooth component’s vulnerabilities and has remote access to the victim’s device.
\ 
\ The complex scenario covers several threats defined in Table I. Table V shows such threats and both the platform functionalities and components that allow the scenario reproduction. The
\ 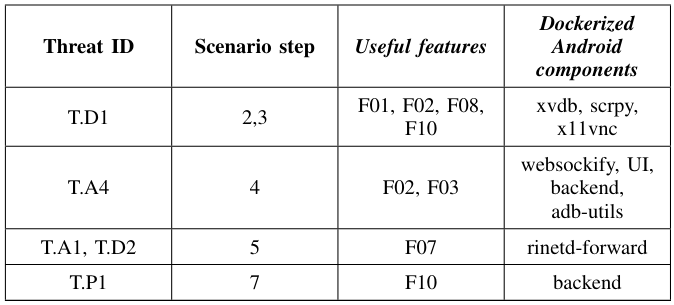
\ scenario requires complex network communications (F07) and involves the utilization of Bluetooth. For this reason, we have to use a physical device (F10). In the proposed scenario, we have to simulate the installation of the malicious application when the user receives the email. This can be done either manually (F02) or by implementing utility ADB scripts (F03). In order to reproduce the scenario, additional elements are needed:
\ • Gophish: a webapp that allows to craft and send phishing emails, for which a Docker version already exists.
\ • Ghidra: an application created by the National Security Agency (NSA) for reverse engineering purposes. In this context, it is used to get some useful information about the target device. This application is used on the host machine without Docker.
\ • Fake Spotify: a seemingly benign application that pretends to provide the user with a free version of the well-known Spotify Premium app, but rather sends to the attacker’s server exfiltrated files that are reverse-engineered on Ghidra. Also, this app was created without the usage of Docker.
\ 
\ It is composed of five services, two of which are the subcomponents of Dockerized Android. The remaining three are briefly described in the following:
\ • attacker_phishing: contains the Gophish component used to craft and send the phishing email that tricks the user into downloading the malicious Fake Spotify app;
\ • attackerwebserver: contains the webserver used to receive the files sent by the malicious app, which are reverse engineered in order to find information allowing the attacker to exploit the vulnerability on the target device;
\ • attacker_blueborne: the service used by the attacker to execute the attack on the target device and obtain a reverse shell on it.
\ E. Requirements coverage
\ In Table II we have illustrated the defined requirements for the realization of our platform. The following table contains all the requirements and their corresponding status:
\ 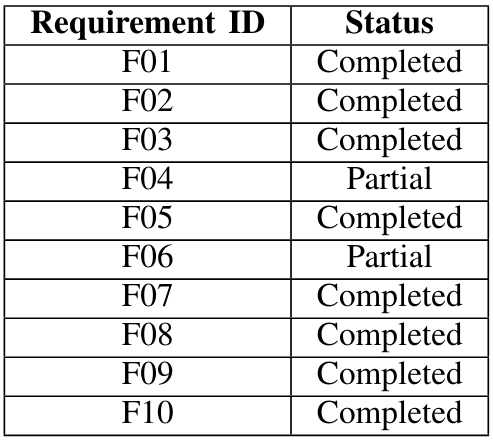
\ Requirement F04, as detailed before, is set to Partial because of the inability to correctly configure all the hardware components (for example the Bluetooth device). Requirement F06 is set to partial because ADB gives the ability to record the screen out-of-the-box, but this feature was not exposed or made easier to use through the UI. Finally, requirements F07 (Network Configuration) and F09 (Third-Party Tools integration) are granted by default because of the usage of Docker. The network can be defined in any possible way through the docker-compose file, and third-party tools can be easily used together with this system.
\
:::info This paper is available on arxiv under CC by-SA 4.0 Deed (Attribution-Sahrealike 4.0 International license.
:::
[1] https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-7661
Ayrıca Şunları da Beğenebilirsiniz

South Korea Launches Innovative Stablecoin Initiative

Trump Cancels Tech, AI Trade Negotiations With The UK
