

連結表格
摘要和1. 引言
1.1 事後解釋
1.2 分歧問題
1.3 鼓勵解釋共識
-
相關工作
-
Pear: 事後解釋器一致性正則化器
-
共識訓練的效果
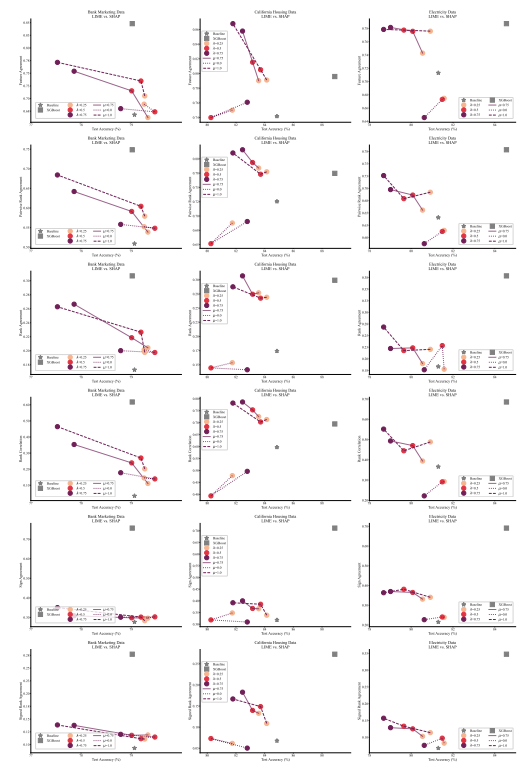
4.1 一致性指標
4.2 改善共識指標
[4.3 一致性的代價是什麼?]()
4.4 解釋是否仍然有價值?
4.5 共識與線性
4.6 兩個損失項
-
討論
5.1 未來工作
5.2 結論、致謝和參考文獻
附錄
A 附錄
A.1 數據集
在我們的實驗中,我們使用了最初來自OpenML的表格數據集,這些數據集由Inria-Soda團隊編譯成HuggingFace上的基準數據集[11]。我們提供每個數據集的一些詳細信息:
\ 銀行營銷 這是一個二元分類數據集,具有六個輸入特徵,並且大致類別平衡。我們在7,933個訓練樣本上進行訓練,並在剩餘的2,645個樣本上進行測試。
\ 加州房價 這是一個二元分類數據集,具有七個輸入特徵,並且大致類別平衡。我們在15,475個訓練樣本上進行訓練,並在剩餘的5,159個樣本上進行測試。
\ 電力 這是一個二元分類數據集,具有七個輸入特徵,並且大致類別平衡。我們在28,855個訓練樣本上進行訓練,並在剩餘的9,619個樣本上進行測試。
A.2 超參數
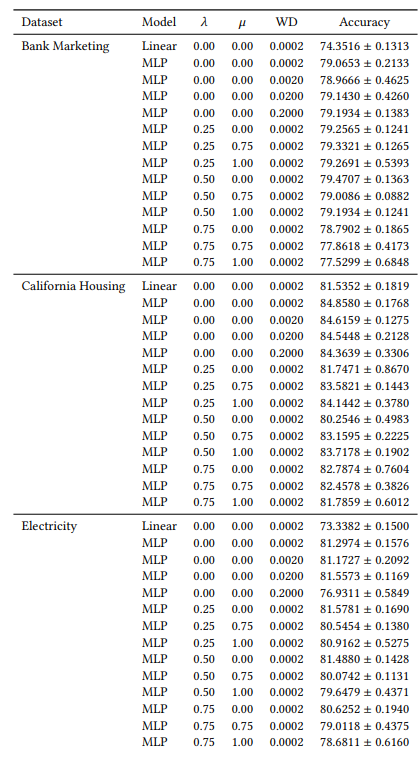
我們的許多超參數在所有實驗中都是恆定的。例如,所有MLP都使用64的批量大小和0.0005的初始學習率進行訓練。此外,我們研究的所有MLP都有3個隱藏層,每層100個神經元。我們始終使用AdamW優化器[19]。訓練的輪數因情況而異。對於所有三個數據集,當𝜆∈{0.0, 0.25}時,我們訓練30個輪次,否則訓練50個輪次。在訓練線性模型時,我們使用10個輪次和0.1的初始學習率。
A.3 分歧指標
我們在此定義我們工作中使用的六個一致性指標。
\ 前四個指標取決於每個解釋中最重要的前k個特徵。讓𝑡𝑜𝑝_𝑓 𝑒𝑎𝑡𝑢𝑟𝑒𝑠(𝐸, 𝑘)表示解釋𝐸中最重要的前k個特徵,讓𝑟𝑎𝑛𝑘 (𝐸, 𝑠)是特徵𝑠在解釋𝐸中的重要性排名,讓𝑠𝑖𝑔𝑛(𝐸, 𝑠)是特徵𝑠在解釋𝐸中重要性分數的符號(正、負或零)。
\ 
\ 接下來的兩個一致性指標取決於每個解釋中的所有特徵,而不僅僅是前k個。讓𝑅是一個根據重要性計算解釋中特徵排名的函數。
\ 
\ (注意:Krishna等人[15]在他們的論文中指出,𝐹應該是由最終用戶指定的一組特徵,但在我們的實驗中,我們使用此指標的所有特徵)。
A.4 垃圾特徵實驗結果
當我們為第4.4節的實驗添加隨機特徵時,我們將特徵數量增加到了兩倍。我們這樣做是為了檢查我們的共識損失是否會通過比自然訓練的模型更頻繁地將不相關特徵放在前K位來損害解釋質量。在表1中,我們報告了每個解釋器在前5個最重要特徵中包含一個隨機特徵的時間百分比。我們觀察到,在整個範圍內,我們沒有看到這些百分比在𝜆 = 0.0(沒有我們共識損失的基準MLP)和𝜆 = 0.5(使用我們共識損失訓練的MLP)之間有系統性增加
\ 
A.5 更多分歧矩陣
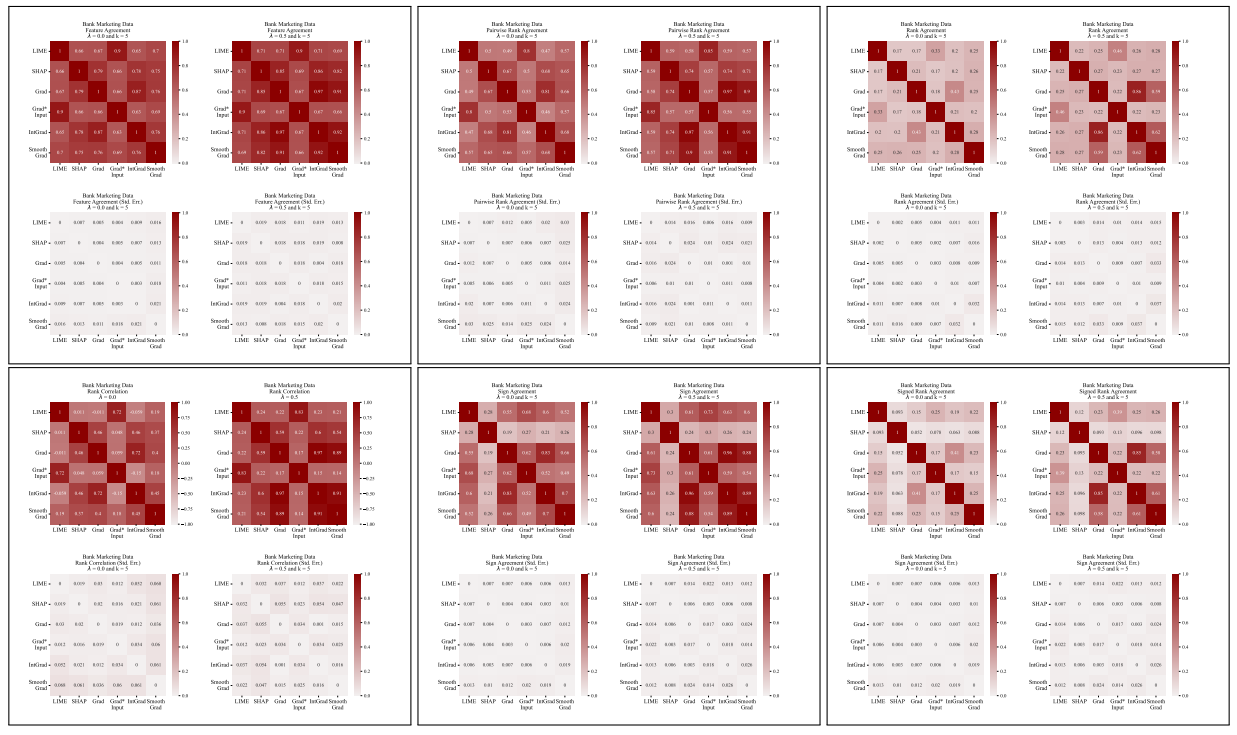
\ 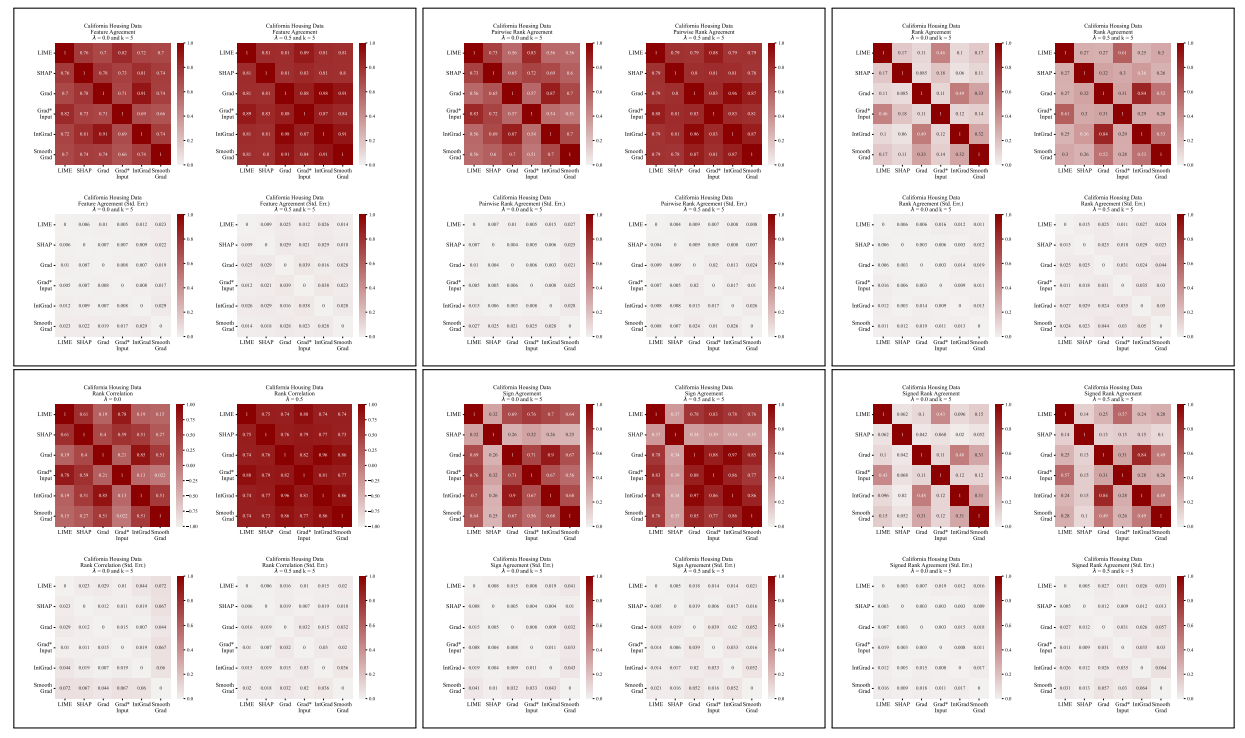
\ 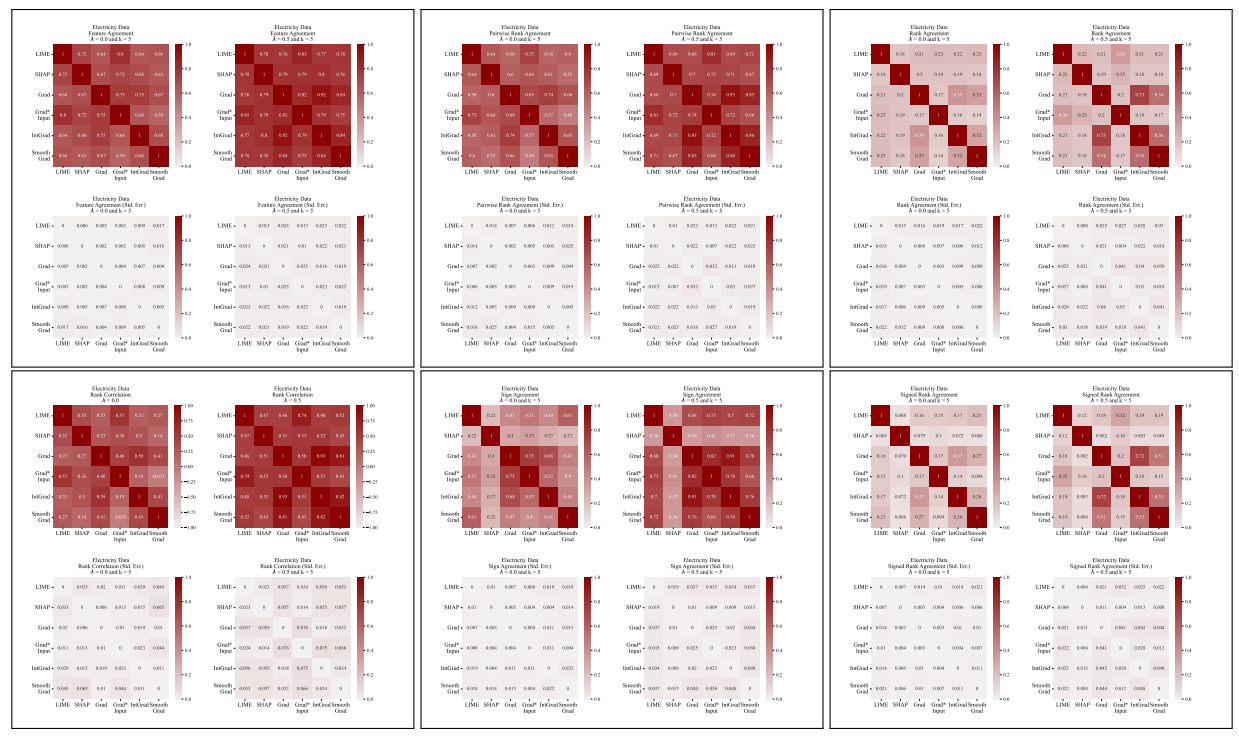
A.6 擴展結果
A.7 額外圖表
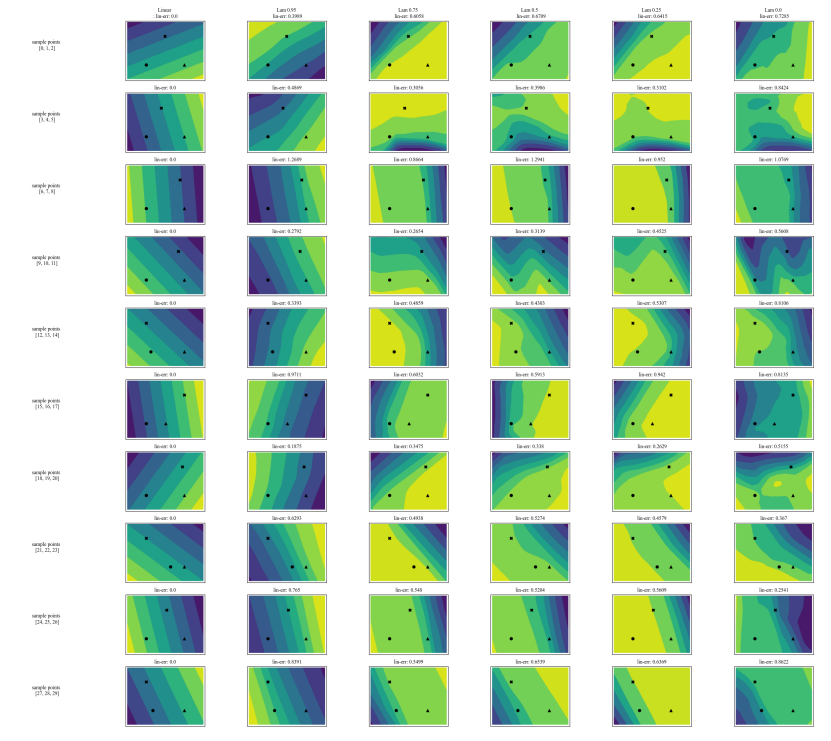
\ 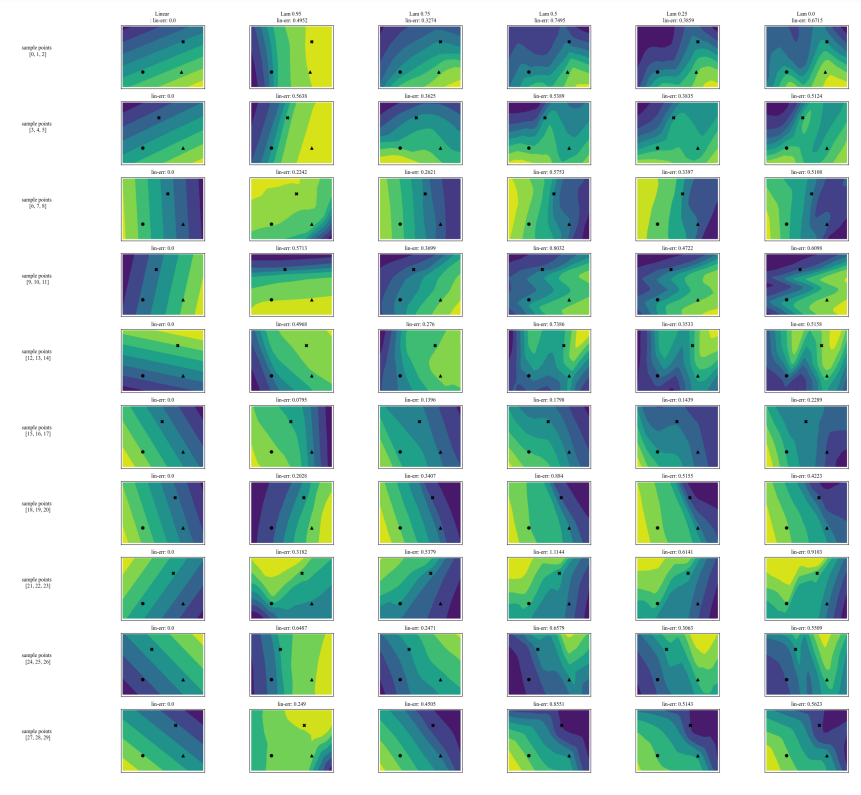
\ 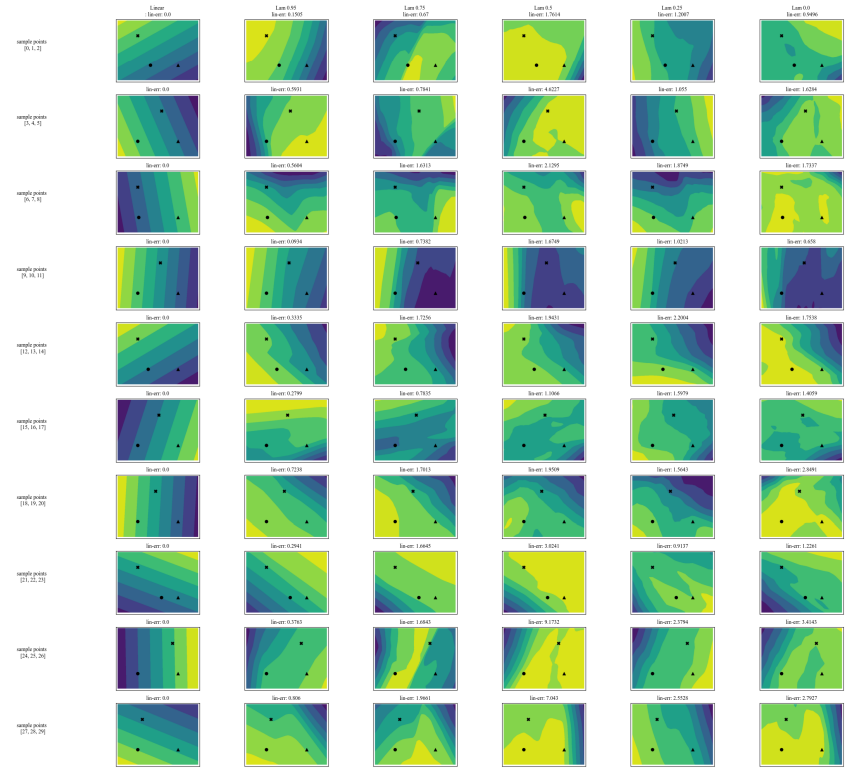
\ 
\
:::info 作者:
(1) Avi Schwarzschild,馬里蘭大學,馬里蘭州學院公園,美國,以及在Arthur工作期間完成的工作(avi1umd.edu);
(2) Max Cembalest,Arthur,紐約市,紐約州,美國;
(3) Karthik Rao,Arthur,紐約市,紐約州,美國;
(4) Keegan Hines,Arthur,紐約市,紐約州,美國;
(5) John Dickerson†,Arthur,紐約市,紐約州,美國(john@arthur.ai)。
:::
:::info 本論文可在arxiv上獲取,根據CC BY 4.0 DEED許可證。
:::
\
您可能也會喜歡

重大消息:Strategy執行長透露若比特幣進一步下跌,他們將無法償還債務的價格水平

加密產業提議與社區銀行共享穩定幣儲備:報導
