


- 原文:《黃仁勳GTC演講全文:推理時代到來,2027營收至少兆美元,龍蝦就是新作業系統》
- 作者:華爾街見聞
2026 年3 月16 日,輝達 GTC 2026 大會正式開幕,輝達創辦人兼CEO 黃仁勳發表了主題演講。
在這場被視為「AI 產業年度朝聖」的大會上,黃仁勳闡述了輝達從一家「晶片公司」向「AI 基礎設施和工廠公司」的轉變。面對市場最關心的業績持續性與成長空間問題,黃仁勳詳細拆解了驅動未來成長的底層商業邏輯—「Token 工廠經濟學」。

業績指引極度樂觀,“2027 年至少1 兆美元的需求”
過去兩年,全球AI 運算需求呈指數級爆炸。隨著大模型從“感知”、“生成”進化到“推理”與“行動(執行任務)”,算力的消耗量急劇攀升。針對市場高度關注的訂單與營收天花板,黃仁勳給出了極為強勁的預期。
黃仁勳在演講中直言:
去年這個時候,我說過,我們看到了5,000 億美元的高確信度需求,涵蓋 Blackwell 和 Rubin 直到2026 年。現在,就在此時此地,我看到到2027 年至少有1 兆美元的需求。

黃仁勳的萬億預期一度推動輝達股價漲超 4.3%。
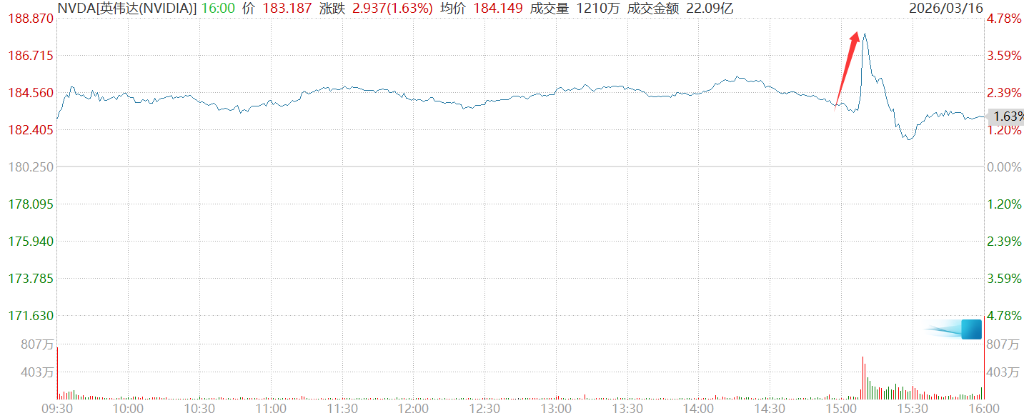
不僅如此,他更是對這數字做出了補充:
這樣合理嗎?這就是我接下來要講的。事實上,我們甚至會供不應求。我確定,實際的計算需求會比這高得多。
黃仁勳指出,如今的輝達系統已經證明了自己是全球「成本最低的基礎設施」。由於輝達能運行幾乎所有領域的 AI 模型,這種通用性使得客戶投入的這 1 兆美元能夠被充分利用並維持長久的生命週期。
目前,輝達 60% 的業務來自排名前五的超大型雲端服務商,另外40%的業務則廣泛分佈於主權雲端、企業、工業、機器人和邊緣運算等各個領域。
Token 工廠經濟學,每瓦性能決定商業命脈
為了解釋這 1 兆需求的合理性,黃仁勳向全球企業CEO 展示了一套全新的商業思維。他指出,未來的資料中心不再是儲存文件的倉庫,而是生產 Token(AI 產生的基本單位)的「工廠」。

黃仁勳強調:
每一座資料中心、每一座工廠,從定義上來說都是受電力限制的。一座 1GW(吉瓦)的工廠永遠不會變成2GW,這是物理和原子的定律。在固定的功率下,誰的每瓦 Token 吞吐量最高,誰的生產成本就最低。
黃仁勳將未來的AI 服務分為四個商業層級:
- 免費層(高吞吐、低速度)
- 中級層(~每百萬token 3 美元)
- 高級層(~每百萬token 6 美元)
- 高速層(~每百萬token 45 美元)
- 超高速層(~每百萬token 150 美元)
他指出,隨著模型越來越大、上下文越來越長,AI 會變得更聰明,但 Token 的生成速率會降低。黃仁勳表示:
在這個 Token 工廠裡,你的吞吐量和 Token 產生速度,將直接轉換為你明年的精確收入。
黃仁勳強調輝達的架構能讓客戶在免費層實現極高的吞吐量,同時在最高價值的推理層級上,將效能提升驚人的 35 倍。

Vera Rubin 兩年達到350 倍加速,Groq 填補極速推理
在這個物理極限的限制下,輝達介紹其有史以來最複雜的 AI 計算系統,Vera Rubin。黃仁勳表示:
過去提到 Hopper,我會舉起一塊晶片,那很可愛。但提到 Vera Rubin,大家想到的是整個系統。在這個100% 液冷、完全消滅了傳統電纜的系統中,過去需要兩天安裝的機架,現在只需兩小時。
黃仁勳指出,透過極致的端對端軟硬體協同設計,Vera Rubin 在同一座 1GW 資料中心裡創造了驚人的資料跨越:
在短短兩年時間內,我們將 Token 的生成速率從 2,200 萬提升到了 7 億,實現了 350 倍的成長。摩爾定律在同時期僅能帶來約 1.5 倍的提升。
為了解決極速推理(如 1000 Tokens/秒)條件下的頻寬瓶頸,輝達給出了整合被收購公司 Groq 的最終方案:非對稱式的分離推理。黃仁勳解釋:
這兩款處理器的特色截然不同。 Groq 晶片擁有 500MB 的 SRAM,而一顆 Rubin 晶片則擁有 288GB 的記憶體。

黃仁勳指出,輝達透過 Dynamo 軟體系統,將需要大量運算和顯存的「預填充(Pre-fill)」階段交給 Vera Rubin,將對延遲極度敏感的「解碼」階段交給 Groq。黃仁勳也對企業算力配置給了建議:
如果你的工作主要是高吞吐,100% 使用 Vera Rubin;如果你有大量高價值的程式設計等級的 Token 生成需求,拿出 25% 的資料中心規模給 Groq。
據透露,由三星代工的 Groq LP30 晶片已在量產,預計第三季出貨,而首個 Vera Rubin 機架已在微軟Azure 雲端上運行。
此外,針對光互聯技術,黃仁勳展示了全球首款量產的共封裝光學(CPO)交換器 Spectrum X,並平息了市場對於「銅退光進」的路線之爭:
我們需要更多的銅纜產能,更多的光晶片產能,更多的 CPO 產能。
Agent 終結傳統SaaS,「年薪+Token」成矽谷標配
除了硬體壁壘,黃仁勳把大量篇幅留給了AI 軟體和生態的革命,特別是 Agent(智能體)的爆發。
他將開源專案 OpenClaw 形容為“人類歷史上最受歡迎的開源專案”,稱其僅用幾週時間就超越了 Linux 在過去30 年取得的成就。黃仁勳直言,OpenClaw 本質上就是 Agent 電腦的「作業系統」。
黃仁勳斷言:
每一個 SaaS(軟體即服務)公司都將變成 AaaS(Agent-as-a-Service,智慧體即服務)公司。毫無疑問,為了讓這種具備存取敏感資料和執行程式碼能力的智能體安全落地,輝達推出了企業級的 NeMo Claw 參考設計,增加了策略引擎和隱私路由器。
對於一般職場人,這場變革同樣近在咫尺。黃仁勳描繪了未來的職場新形態:
在未來,我們公司的每位工程師都需要一個年度 Token 預算。他們的基本年薪可能是幾十萬美元,我會在此基礎上再拿出大約一半的金額作為 Token 額度給他們,讓他們實現 10x 的效率提升。這已經是矽谷的新招募籌碼了:你的 offer 裡帶多少 Token?
演講最後,黃仁勳也「劇透」了下一代運算架構 Feynman,它將首次實現銅線與 CPO 的共同水平擴展。更引人遐想的是,輝達正在研發部署在太空的資料中心電腦“Vera Rubin Space-1”,徹底打開了AI 算力向地球之外延伸的想像空間。
黃仁勳GTC 2026 演講全文,全文翻譯如下(AI 工具輔助):
主持人:歡迎輝達創辦人兼執行長黃仁勳上台。
黃仁勳,創辦人兼執行長:
歡迎來到 GTC。我想提醒大家,這是一場技術大會。能看到這麼多人一大早排隊入場,能看到在座的各位,我感到非常高興。
在GTC,我們將聚焦在三大主題:技術、平台和生態系統。輝達目前有三大平台:CUDA-X 平台、系統平台,以及我們最新推出的AI 工廠平台。
在正式開始之前,我要感謝我們的預熱環節主持人——Conviction 的 Sarah Guo、紅杉資本的 Alfred Lin(輝達的第一位創投),以及輝達的第一位主要機構投資人 Gavin Baker。這三位對科技有深刻的洞見,在整個科技生態系中擁有極廣的影響力。當然,我還要感謝今天所有我親自邀請出席的貴賓們。感謝這支全明星團隊。
我同樣要感謝今天到場的所有企業。輝達是一家平台公司,我們擁有技術、平台和豐富的生態系統。今天到場的企業代表了價值100 兆美元產業中幾乎全部的參與者,共有450 家公司贊助了本次活動,在此深表感謝。
本次大會共設有1,000 場技術論壇、2,000 位演講嘉賓,將涵蓋人工智慧”五層蛋糕”架構的每一個層級-從土地、電力與機房等基礎設施,到晶片、平台、模型,以及最終推動整個產業騰飛的各類應用。
CUDA:二十年的技術累積
一切的起點,就在這裡。今年是CUDA 誕生二十週年。
二十年來,我們始終致力於這項架構的研發。 CUDA 是一項革命性的發明——SIMT(單指令多執行緒)技術允許開發者以標量程式碼編寫程序,並將其擴展為多執行緒應用,其程式設計難度遠低於先前的 SIMD 架構。我們最近也新增了 Tiles 功能,幫助開發者更方便地編程張量核心(Tensor Core),以及當今人工智慧所依賴的各類數學運算結構。目前,CUDA 已擁有數千種工具、編譯器、框架和函式庫,在開源社群中存在數十萬個公開項目,並已深度整合到每個技術生態系統之中。
這張圖表揭示了輝達 100%的策略邏輯,我從最初就一直在講這張投影片。其中最難實現、也是最核心的要素,是圖表底部的”裝機量”。歷經二十年,我們已在全球累積了數億塊運行 CUDA 的 GPU 和運算系統。
我們的 GPU 涵蓋所有雲端平台,服務幾乎所有電腦廠商和產業。 CUDA 龐大的裝置量,正是這個飛輪不斷加速的根本原因。裝機量吸引開發者,開發者創造新演算法並取得突破,突破催生全新市場,新市場形成新生態並吸引更多企業加入,進而擴大裝機量——這個飛輪正在持續加速。
輝達庫的下載量正以驚人的速度成長,規模龐大且成長不斷提升。這個飛輪使我們的運算平台能夠支撐海量應用和層出不窮的新突破。
更重要的是,它也賦予了這些基礎設施極長的使用壽命。原因顯而易見:NVIDIA CUDA 上可運作的應用極為豐富,涵蓋AI 生命週期的每個階段、各類資料處理平台,以及各種科學原理解算器。因此,一旦安裝了輝達 GPU,其實際使用價值極高。這也是為何我們六年前發布的 Ampere 架構 GPU,其雲端價格反而在上漲。
這一切的根本原因在於:裝置容量龐大,飛輪強勁,開發者生態廣泛。當這些因素共同發揮作用,加上我們持續更新軟體,計算成本就會不斷下降。加速運算在大幅提升應用效能的同時,隨著我們長期維護和迭代軟體,使用者不僅能在初期獲得效能躍升,還能持續享受運算成本的下降。我們願意為全球每一塊GPU 提供長期支持,因為它們在架構上完全相容。
我們之所以願意這麼做,是因為裝置量如此龐大──每發布一次新的優化,就能惠及數百萬用戶。這種動態組合,使得輝達架構在持續擴大覆蓋範圍、加速自身成長的同時,不斷壓低運算成本,最終刺激新的成長。 CUDA 是這一切的核心。
從GeForce到CUDA:二十五年的演進之路
而我們與 CUDA 的旅程,其實早在二十五年前就已經開始。
GeForce-相信在座有很多人是伴隨著 GeForce 長大的。 GeForce 是輝達最成功的市場推廣計畫。我們從你們還買不起產品的時候就開始培養未來的客戶——是你們的父母代替你們成為了輝達最早的用戶,年復一年地購買我們的產品,直到有一天,你們成長為優秀的計算機科學家,成為真正意義上的客戶和開發者。
這是二十五年前 GeForce 奠定的基業。二十五年前,我們發明了可程式著色器——這是讓加速器實現可程式化的一項顯而易見卻意義深遠的發明,也是世界上第一款可程式加速器,也就是像素著色器。這五年後,我們創造了 CUDA——這是我們有史以來最重要的投資之一。當時公司財力有限,但我們將絕大部分利潤押注於此,致力於將 CUDA 從 GeForce 延伸到每台電腦。我們之所以如此堅定,是因為我們深信其潛力。儘管初期歷經艱辛,公司堅守這項信念長達 13 代、整整二十年,如今 CUDA 已無所不在。
正是像素著色器推動了 GeForce 的革命。而大約八年前,我們推出了 RTX——為現代電腦繪圖時代對架構進行了全面革新。 GeForce 將 CUDA 帶給了全世界,也正因如此,讓 Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton、Andrew Ng 等眾多學者發現,GPU 可以成為加速深度學習的利器,由此點燃了十年前人工智慧的大爆炸。
十年前,我們決定將可程式著色與兩個全新理念融合:一是硬體光線追蹤(Ray Tracing),這在技術上極具挑戰;二是一個當時頗具前瞻性的想法——大約十年前,我們就預見到AI 將徹底變革電腦圖形。正如GeForce 將AI 帶給了全世界,AI 如今也將反過來重塑整個電腦圖形的實現方式。
今天,我要向大家展示未來。這是我們的下一代圖形技術,我們稱之為神經渲染(Neural Rendering)——3D 圖形與人工智慧的深度融合。這就是DLSS 5,請看。
神經渲染:結構化資料與生成式AI 的融合
這是不是令人嘆為觀止?計算機圖形就此煥發生機。
我們做了什麼?我們將可控的 3D 圖形(虛擬世界的真實基礎)與其結構化資料結合,再融入生成式AI 和機率計算。一個完全確定性,另一個機率性卻高度逼真——我們將這兩種理念融為一體,透過結構化資料實現精準可控,同時進行即時生成。最終,內容美觀驚艷,又完全可控。
結構化資訊與生成式 AI 融合這一理念,將在一個又一個行業中不斷復現。結構化資料是可信 AI 的基石。
結構化資料與非結構化資料的加速平台
現在我要帶大家來看一張技術架構圖。
結構化資料-大家熟悉的 SQL、Spark、Pandas、Velox,以及Snowflake、Databricks、Amazon EMR、Azure Fabric、Google BigQuery 等重要平台,都在處理資料框(Data Frame)。這些數據框就像巨型電子表格,承載著商業世界的全部信息,是企業計算的基本事實(Ground Truth)。
在AI 時代,我們需要讓 AI 來使用結構化數據,並對其實現極致加速。過去,加速結構化資料處理是為了讓企業更有效率地運作。而未來,AI 將以遠超人類的速度使用這些資料結構,AI 智能體也將大量調用結構化資料庫。
非結構化資料方面,向量資料庫、PDF、視訊、音訊等構成了世界上絕大多數的資料形態-每年產生的資料中,約90%是非結構化資料。過去,這些數據幾乎完全無法被利用:我們讀取它們,存入檔案系統,僅此而已。我們無法查詢,也難以檢索,原因在於非結構化資料缺乏簡單的索引方式,必須理解其意義與脈絡。而現在,AI 可以做到這一點——借助多模態感知與理解技術,AI 能夠讀取PDF 文件、理解其含義,並將其嵌入可供查詢的更大結構之中。
輝達為此創建了兩個基礎函式庫:
- cuDF:用於資料框、結構化資料的加速處理
- cuVS:用於向量儲存、語意資料和非結構化AI 資料的處理
這兩個平台將成為未來最重要的基礎平台之一。
今天,我們宣布與多家企業達成合作。 IBM-SQL 語言的發明者,將使用 cuDF 加速其 WatsonX Data 平台。 Dell 與我們共同打造了 Dell AI 資料平台,整合 cuDF 與 cuVS,並在 NTT Data 的實際專案中實現了大幅效能提升。 Google Cloud 方面,我們現在不僅加速 Vertex AI,還加速 BigQuery,並與 Snapchat 合作將其運算成本降低了近 80%。
加速運算帶來的好處是三位一體的:速度、規模、成本。這與摩爾定律的邏輯一脈相承——透過加速運算實現效能飛躍,同時持續優化演算法,讓所有人都能享受到持續下降的運算成本。
輝達建構了加速運算平台,其上匯聚了眾多函式庫:RTX、cuDF、cuVS 等等。這些函式庫整合進全球雲端服務和OEM 體系,共同觸達全球用戶。
與雲端服務商的深度合作
與主要雲端服務商的合作
Google Cloud:我們加速 Vertex AI和 BigQuery,與 JAX/XLA 深度集成,同時在 PyTorch 上表現卓越——輝達是全球唯一一家在PyTorch和JAX/XLA 上均表現出色的加速器。我們將Base10、CrowdStrike、Puma、Salesforce 等客戶引進Google Cloud 生態。
AWS:我們加速EMR、SageMaker和Bedrock,與AWS 有深度整合。今年令我格外興奮的是,我們將把OpenAI 引入AWS,這將大幅推動AWS 雲端運算的消耗成長,幫助OpenAI 擴展區域部署和運算規模。
Microsoft Azure:輝達 100 PFLOPS 超算是我們建造的第一台超級計算機,也是第一台部署在Azure 上的超算,這奠定了與OpenAI 合作的重要基礎。我們加速Azure 雲端服務和AI Foundry,合作推動Azure 區域擴展,並在Bing 搜尋上深度協作。值得一提的是,我們的**保密運算(Confidential Computing)**能力-確保即使是營運商也無法查看使用者資料和模型-輝達 GPU 是全球首批支援保密運算的GPU,可支援OpenAI和Anthropic 模式在全球各地區雲端環境中的保密部署。以Synopsys 為例,我們加速其全部EDA和CAD 工作流程,並部署於Microsoft Azure。
Oracle:我們是Oracle 的第一個AI 客戶,我為能夠第一次向Oracle 解釋AI 雲端的概念感到自豪。此後他們發展迅速,我們也為其引進了Cohere、Fireworks、OpenAI 等眾多合作夥伴。
CoreWeave:全球第一家AI 原生雲,專為GPU 託管和AI 雲端服務而生,擁有出色的客戶群,成長勢頭強勁。
Palantir + Dell:三方聯合打造了全新的AI 平台,基於Palantir 的本體論平台(Ontology Platform)和AI 平台,可在任何國家、任何氣隙隔離環境下、完全本地化地部署AI——從數據處理(向量化或結構化)到AI 的完整加速計算棧,無所不包。
輝達與全球雲端服務商建立了這種特殊的合作關係-我們將客戶引入雲端,這是一種互利共贏的生態。
垂直整合,橫向開放:輝達的核心策略
輝達是全球第一家垂直整合、橫向開放的公司。
這一模式的必要性非常簡單:加速運算不是晶片問題,也不是系統問題,其完整表述應為應用加速。 CPU 可以讓電腦整體運作得更快,但這條路已走到瓶頸。未來,只有透過應用或領域特定的加速,才能持續帶來效能飛躍和成本下降。
這正是輝達必須深耕一個又一個庫、一個又一個領域、一個又一個垂直行業的原因。我們是一家垂直整合的計算公司,沒有其他路可走。我們必須理解應用,理解領域,深刻理解演算法,並能夠將其部署在任何場景下——資料中心、雲端、本地、邊緣甚至機器人系統。
同時,輝達保持橫向開放,願意將科技整合進任何合作夥伴的平台,讓全世界都能享受到加速運算的紅利。
本屆GTC 的與會者結構充分體現了這一點。本次與會者中,金融服務業的比例最高-希望來的是開發者,不是交易者。我們的生態系覆蓋了上游和下游供應鏈。無論是成立50 年、70 年或150 年的企業,去年都迎來了歷史最佳年份。我們正處於某件非常、非常重大的事情的起點。
CUDA-X:各行業的加速運算引擎
在各個垂直領域,輝達均已深度佈局:
- 自動駕駛:覆蓋範圍廣泛,影響深遠
- 金融服務:量化投資正從人工特徵工程轉向超級電腦驅動的深度學習,迎來其”Transformer 時刻”
- 醫療健康:正在迎來屬於自己的”ChatGPT 時刻”,涵蓋AI 輔助藥物發現、AI 智能體支持診斷、醫療客服等方向
- 工業:全球規模最大的建設浪潮正在展開,AI 工廠、晶片廠、資料中心廠紛紛落地
- 娛樂與遊戲:即時AI 平台支援翻譯、直播、遊戲互動,以及智慧購物代理
- 機器人:深耕十餘年,三大電腦架構(訓練電腦、模擬電腦、機載電腦)齊備,本次展會共有110 款機器人亮相
- 電信:約2 兆美元規模的產業,基地台將從單一通訊功能演進為AI 基礎設施平台,相關平台名為Aerial,與諾基亞、T-Mobile 等企業均有深度合作
以上所有領域的核心,正是我們的CUDA-X 函式庫-這就是輝達作為演算法公司的根本所在。這些庫是公司最核心的資產,讓運算平台得以在各行業發揮實際價值。
其中最重要的庫之一,是cuDNN(CUDA 深度神經網路庫),它徹底革新了人工智慧,引發了現代AI 的大爆炸。
(播放CUDA-X 示範影片)
大家剛才看到的一切都是模擬——包括基於物理原理的解算器、AI 代理物理模型,以及實體AI 機器人模型。一切均為仿真,沒有任何手工動畫或關節綁定。這正是輝達的核心能力所在:透過對演算法的深刻理解與運算平台的有機結合,解鎖這些機會。
AI 原生企業與新運算時代
你們剛才看到了沃爾瑪、歐萊雅、摩根大通、羅氏、豐田等定義當今社會的行業巨頭,也有一大批大家從未聽說過的公司——我們稱之為AI 原生企業。這份名單極為龐大,裡面有OpenAI、Anthropic,以及許多服務不同垂直領域的新創企業。
過去兩年,這一行業經歷了驚人的起飛。創投流入新創企業的資金規模達到1,500 億美元,創人類歷史之最。更重要的是,單筆投資規模首次從數百萬美元躍升至數億甚至數十億美元。原因只有一個:這是史上第一次,每家這類公司都需要大量運算資源和大量token。這個產業正在創造、產生token,或為來自Anthropic、OpenAI 等機構的token 增值。
正如PC 革命、網路革命、行動雲革命各自孕育出一批劃時代的企業,這一代運算平台變革同樣將誕生一批極具影響力的公司,成為未來世界的重要力量。
推動這一切的三大歷史性突破
過去兩年究竟發生了什麼事?三件大事。
第一:ChatGPT,開啟生成式AI 時代(2022 年底至2023 年)
它不僅能感知和理解,還能產生獨特內容。我展示了生成式AI 與電腦圖形的融合。生成式AI 從根本上改變了運算的方式——計算從檢索式轉變為生成式,這深刻影響著電腦架構、部署方式和整體意義。
第二:推理AI(Reasoning AI),以o1 為代表
推理能力使AI 能夠自我反思、規劃、分解問題——將它無法直接理解的問題拆解為可處理的步驟。 o1 讓生成式AI 變得可信,能夠依據真實資訊進行推理。為此,輸入context的token 量和用於思考的輸出token 量大幅增加,計算量隨之顯著提升。
第三:Claude Code,首個智能體模型
它能讀取檔案、編寫程式碼、編譯、測試、評估並迭代。 Claude Code 徹底革新了軟體工程——輝達100%的工程師都在使用Claude Code、Codex和Cursor 中的一種或多種,沒有一位軟體工程師不借助AI 助力。
這是一個全新的轉折點——你不再是詢問AI”是什麼、在哪裡、怎麼做”,而是讓它”創建、執行、構建”,讓它主動使用工具、讀取文件、分解問題、付諸行動。 AI 從感知,到生成,到推理,再到如今真正能夠完成工作。
過去兩年,推理所需的計算量增加了約10,000 倍,使用量增加了約100 倍。我一直認為,過去兩年計算需求增加了100 萬倍——這是所有人的共同感受,是OpenAI 的感受,是Anthropic 的感受。如果能獲得更多算力,就能產生更多token,收入就會提升,AI 就會變得更智能。推理拐點已然到來。
兆美元的AI 基礎設施時代
去年此時,我在這裡表示,我們對Blackwell和Rubin 在2026 年之前的需求和採購訂單有高度信心,規模約為5,000 億美元。今天,在GTC 一年後,我站在這裡告訴大家:展望到2027 年,我看到的數字至少是1 兆美元。而且我確信,實際的運算需求將遠不止於此。
2025:輝達推理年
2025 年是輝達的推理年(Year of Inference)。我們希望確保,在訓練和後訓練之外,也能在AI 生命週期的每個階段都保持卓越,使已投資的基礎設施能夠持續高效運轉,且有效使用壽命越長,單位成本越低。
同時,Anthropic和Meta 正式加入NVIDIA 平台,與此共同代表了全球三分之一的AI 算力需求。開源模型已接近前沿水平,無處不在。
輝達是目前全球唯一能夠運作所有AI 領域——語言、生物學、電腦圖形、電腦視覺、語音、蛋白質與化學、機器人等——所有AI 模型的平台,無論邊緣或雲端,無論何種語言。輝達架構對所有這些場景均具備通用性,這使我們成為成本最低、置信度最高的平台。
目前,輝達 60%的業務來自全球前五大超大規模雲端服務商,剩餘40%遍及區域雲端、主權雲端、企業、工業、機器人、邊緣運算等各個領域。 AI 的覆蓋廣度本身就是其韌性所在——這毫無疑問是全新的運算平台變革。
Grace Blackwell與NVLink 72:大膽的架構革新
在Hopper 架構仍處於鼎盛時期,我們就決定徹底重新架構系統,將NVLink 從8 路擴展為NVLink 72,對運算系統進行全面分解重構。 Grace Blackwell NVLink 72 是巨大的技術押注,對所有合作夥伴而言都不容易,在此向所有人表示誠摯感謝。
同時,我們推出了NVFP4——不只是普通的FP4,而是一種全新類型的張量核心和運算單元。我們已經證明,NVFP4 可以在無精度損失的情況下實現推理,同時帶來巨大的性能提升和能源效率提升,並且同樣適用於訓練。此外,Dynamo和TensorRT-LLM 等一系列新演算法相繼問世,我們甚至為優化核心而專門投入數十億美元建造了一台超級計算機,稱之為DGX Cloud。
結果證明,我們的推理表現令人矚目。來自Semi Analysis 的數據——這是迄今為止最全面的AI 推理性能評測——顯示輝達在每瓦token 數和每token 成本兩個維度上均遙遙領先。原本摩爾定律可能為H200 帶來1.5 倍的效能提升,但我們做到了35 倍。 Semi Analysis的Dylan Patel 甚至說:「黃仁勳保守了,實際上是50 倍。」他說得沒錯。
我在此引用他的話:”Jensen sandbagged(黃仁勳保守報數)。”
輝達的每token 成本是全球最低,目前無人能及。原因正極致協同設計(Extreme Co-design)。
以Fireworks 為例,在輝達更新全套軟體和演算法之前,其平均token 速度約為每秒700 個;更新後接近每秒5,000 個,提升約7 倍。這就是極致協同設計的力量。
AI 工廠:從資料中心到token 工廠
資料中心過去是儲存檔案的地方,現在它是生產token 的工廠。每一家雲端服務商、每一家AI 公司,未來都將以”token 工廠效率”作為核心經營指標。
這是我的核心論點:
- 縱軸:吞吐量(Throughput)-在固定功率下每秒產生的token 數
- 橫軸:互動速度(Token Speed)-每次推理的反應速度,速度越快,可使用的模型越大、context 越長,AI 越智能
token 是新的大宗商品,一旦成熟,將分層定價:
- 免費層(高吞吐、低速度)
- 中級層(~每百萬token 3 美元)
- 高級層(~每百萬token 6 美元)
- 高速層(~每百萬token 45 美元)
- 超高速層(~每百萬token 150 美元)
與Hopper 相比,Grace Blackwell 在最高價值層提升了35 倍吞吐量,並引入全新層級。以簡化模型估算,將25%功率分別分配給四個層級,Grace Blackwell 可比Hopper 多產生5 倍的收入。
Vera Rubin:下一代AI 計算系統
(播放Vera Rubin 系統介紹影片)
Vera Rubin 是一個完整的、端對端優化的系統,專為智能體(Agentic)工作負載設計:
- 大型語言模型運算核心:NVLink 72 GPU 集群,處理前填充(Prefill)和KV Cache
- 全新Vera CPU:專為極高單線程性能設計,採用LPDDR5 內存,兼具卓越能效,是全球唯一使用LPDDR5 的數據中心CPU,適合AI 智能體工具調用
- 儲存系統:BlueField 4 + CX 9,針對AI 時代的全新儲存平台,全球儲存產業100%加入
- CPO Spectrum X 交換器:全球首款共封裝光學乙太網路交換機,已全面量產
- Kyber 機架:全新機架系統,支援144塊GPU 組成單一NVLink 域,前端運算、後端NVLink 交換,形成一台巨型計算機
- Rubin Ultra:下一代超算節點,垂直設計,配合Kyber 機架,支援更大規模NVLink 互聯
Vera Rubin 已100%液冷,安裝時間從兩天縮短至兩小時,採用45°C 熱水冷卻,大幅降低資料中心冷卻壓力。這次Satya(納德拉)已發文確認,首台Vera Rubin 機架已在微軟Azure 上線運行,我為此深感振奮。
Groq 整合:推理表現的極致延伸
我們收購了Groq 團隊並獲得其技術授權。 Groq 是一種確定性資料流處理器(Deterministic Dataflow Processor),採用靜態編譯和編譯器調度,擁有大量SRAM,專為推理單一工作負載優化,具備極低延遲和極高token 生成速度。
然而,Groq 的記憶體容量有限(500MB 片上SRAM),難以獨立承載大模型的參數和KV Cache,限制了其大規模應用。
解決方案正是Dynamo——一套推理調度軟體。我們透過Dynamo 將推理管線解聚(Disaggregate):
- **前填充(Prefill)及注意力機制的解碼(Decode)**在Vera Rubin 上完成(需要大量算力和KV Cache 儲存)
- **前饋網路解碼(Feed-Forward Network Decode)**即token 產生部分,在Groq 上完成(需要極高頻寬和低延遲)
兩者透過乙太網路緊密耦合,借助特殊模式將延遲減少約一半。在Dynamo 這項”AI 工廠作業系統”的統一調度下,整體效能提升35 倍,並開啟了NVLink 72 先前無法觸及的全新推理效能層級。
Groq與Vera Rubin 的組合建議:
- 若工作負載以高吞吐為主,使用100% Vera Rubin
- 若大量工作負載為程式碼生成等高價值token 生成,可引入Groq,建議比例約25% Groq + 75% Vera Rubin
Groq LP30 由三星代工,目前已進入量產,預計Q3 開始出貨。感謝三星的全力配合。
推理性能的歷史性飛躍
將先前技術進步量化:在2 年時間內,1 吉瓦AI 工廠的token 生成速率將從2,200萬token/秒提升至7億token/秒,提升350 倍。這就是極致協同設計的力量。
技術路線圖
- Blackwell:目前在產,Oberon 標準機架系統,銅纜擴展至NVLink 72,可選光學擴展至NVLink 576
- Vera Rubin(目前):Kyber 機架,NVLink 144(銅纜);Oberon 機架,NVLink 72 + 光學,擴展至NVLink 576;Spectrum 6,全球首款CPO 交換機
- Vera Rubin Ultra(即將推出):新一代Rubin Ultra GPU,LP35 晶片(首次整合NVFP4),進一步提升數倍效能
- Feynman(下一代):全新GPU,LP40 晶片(由輝達與Groq 團隊共同打造,整合NVFP4);全新CPU-Rosa(Rosalyn);BlueField 5;CX 10;同時支援銅纜與CPO 兩種擴充方式的Kyber 機架
路線圖明確:銅纜擴展、光學擴展(Scale-Up)、光學擴展(Scale-Out)三條路線並行推進,我們需要所有合作夥伴在銅纜、光纖和CPO 方面持續擴充。
NVIDIA DSX:AI 工廠的數位孿生平台
AI 工廠越來越複雜,但組成它的各類技術供應商過去從未在設計階段相互協作,直到在資料中心才”相遇”——這顯然不夠。
為此,我們創建了Omniverse,以及基於其上的NVIDIA DSX 平台——一個供所有合作夥伴在虛擬世界中共同設計和運營吉瓦級AI 工廠的平台。 DSX 提供:
- 機架級機械、熱學、電氣、網路模擬系統
- 與電網的連接,實現協同節能調度
- 資料中心內基於Max-Q 的動態功耗和冷卻優化
保守估計,這套系統可將能源利用效率提升約2 倍,在我們談論的規模上,這是非常可觀的效益。 Omniverse 從數位地球開始,將承載各種規模的數位孿生,我們正與全球合作夥伴共同建造人類歷史上最大的電腦。
此外,輝達正在進軍太空。 Thor 晶片已通過輻射認證,正在衛星中運行。我們正與合作夥伴開發Vera Rubin Space-1,用於建造太空資料中心。在太空中只能依靠輻射散熱,熱管理是核心挑戰,我們正集結頂尖工程師攻關。
OpenClaw:智能體時代的作業系統
Peter Steinberger 開發了一款名為OpenClaw 的軟體。這是人類史上最受歡迎的開源項目,在短短幾週內就超越了Linux 三十年的成就。
OpenClaw 本質上是一個智能體系統(Agentic System),能夠:
- 管理資源,存取工具、檔案系統和大型語言模型
- 執行調度、定時任務
- 將問題逐步分解,並呼叫子智能體
- 支援任意模態的輸入輸出(語音、視訊、文字、郵件等)
用作業系統的語法來描述,它確實就是一個作業系統──智能體電腦的作業系統。 Windows 讓個人電腦成為可能,OpenClaw 讓個人智能體成為可能。
每家企業都需要製定自己的OpenClaw 策略,就像我們都需要Linux 策略、HTML 策略、Kubernetes 策略一樣。
企業IT 的全面重塑
OpenClaw 之前的企業IT:資料和文件進入系統,流經工具和工作流程,最終變成人類使用的工具。軟體公司創建工具,系統整合商(GSI)和顧問公司幫助企業使用這些工具。
OpenClaw 之後的企業IT:每一家SaaS 公司都將轉變為AaaS(Agentic as a Service,智能體即服務)公司-不只是提供工具,而是提供專精特定領域的AI 智能體。
但這裡有一個關鍵挑戰:企業內部的智慧體可以存取敏感資料、執行程式碼、與外部通訊。這在企業環境中必須嚴格管控。
為此,我們與Peter 合作,將安全性融入企業級版本,推出了:
- NeMo Claw(參考設計):基於OpenClaw 的企業級參考框架,整合NVIDIA 的全套智慧體AI 工具包
- Open Shield(安全層):已整合至OpenClaw,提供策略引擎、網路護欄、隱私路由,確保企業資料安全
- NeMo Cloud:可下載使用,並與所有SaaS 企業的策略引擎對接
這是企業IT 的文藝復興,一個原本2 兆美元規模的產業,即將成長為數萬億美元規模,從提供工具轉向提供專業化的AI 智能體服務。
我完全可以預見:未來,公司裡的每位工程師都將擁有年度token 預算。他們年薪可能幾十萬美元,我會額外給他們相當於薪資一半的token 配額,讓他們的產出放大10 倍。 “入職附帶多少token 配額”已經成為矽谷的新晉招聘話題。
每家企業未來都將既是token 的使用者(供工程師使用),也是token 的生產者(為其客戶提供服務)。 OpenClaw 的意義不可小覷,它和HTML、Linux 一樣重要。
NVIDIA 開放模式倡議
在自訂智能體(Custom Claw)方面,我們提供了NVIDIA 自研的前沿模型:
模式領域Nemotron 大型語言模式Cosmos 世界基礎模式(World Foundation Model)GROOT 通用人形機器人模式Alpamayo 自動駕駛BioNeMo 數位生物學Phys-AIAI 物理
我們在每個領域都處於技術前沿,並承諾持續迭代——Nemotron 3 之後有Nemotron 4,Cosmos 1 之後有Cosmos 2,Groq 也將迭代到第二代。
Nemotron 3在OpenClaw 中名列全球三大最佳模型之列,處於前沿水平。 Nemotron 3 Ultra 將成為有史以來最強的基礎模型,支持各國建構主權AI。
今天,我們宣布成立Nemotron 聯盟,投資數十億美元推進AI 基礎模型研發。聯盟成員包括:BlackForest Labs、Cursor、LangChain、Mistral、Perplexity、Reflection、Sarvam(印度)、Thinking Machines(Mira Murati 的實驗室)等。一個又一個企業軟體公司加入,將NeMo Claw 參考設計和NVIDIA 智能體AI 工具包整合到自身產品中。
物理AI 與機器人
數位智能體在數位世界中行動——撰寫程式碼、分析數據;而實體AI 是具身化的智能體,也就是機器人。
本次GTC 共有110 款機器人亮相,幾乎囊括了全球所有機器人研發企業。輝達提供三台電腦(訓練電腦、模擬電腦、機載電腦)和完整的軟體堆疊及AI 模型。
自動駕駛方面,自動駕駛的”ChatGPT 時刻”已經到來。今天,我們宣布四家新合作夥伴加入輝達RoboTaxi Ready 平台:比亞迪、現代、日產、吉利,合計年產量1,800 萬輛。加上先前的賓士、豐田、通用,陣容進一步壯大。我們同時宣布與Uber 達成重大合作,將在多個城市部署並連接RoboTaxi Ready 車輛。
工業機器人方面,ABB、Universal Robotics、KUKA 等眾多機器人企業與我們合作,將實體AI 模型與模擬系統結合,推動機器人在全球製造產線的落地。
電信方面,卡特彼勒(Caterpillar)和T-Mobile 也在其列。未來,無線基地台將不再只是一個通訊節點,而是一個NVIDIA Aerial AI RAN——能夠即時感知流量、調整波束成形,實現節能增效的智慧化邊緣運算平台。
特別環節:Olaf 機器人亮相
(播放Disney Olaf 機器人示範影片)
黃仁勳: 雪人登場! Newton 運作正常! Omniverse 也運作正常! Olaf,你好嗎?
Olaf: 見到你我真的太開心了。
黃仁勳: 是的,因為是我給了你電腦-Jetson!
Olaf: 那是什麼?
黃仁勳: 就在你的肚子裡。
Olaf: 太神奇了。
黃仁勳: 你是在Omniverse 學會走路的。
Olaf: 我喜歡走路。這比騎馴鹿仰望美麗的天空好多了。
黃仁勳: 這正是因為物理模擬——基於NVIDIA Warp 運行的Newton 求解器,這是我們與Disney和DeepMind 共同開發的,讓你能夠適應真實的物理世界。
Olaf: 我正想說這個。
黃仁勳: 這就是你聰明的地方。我是雪人,不是雪球。
黃仁勳: 你能想像嗎?未來的迪士尼樂園——所有這些機器人角色在園區自由漫步。不過說實話,我以為你會比較高。我從來沒見過這麼矮的雪人。
Olaf: (不置可否)
黃仁勳: 來幫我結束今天的演講好嗎?
Olaf: 太棒啦!
主題演講總結
黃仁勳:今天,我們共同探討了以下核心主題:
- 推理拐點的到來:推理已成為AI 最核心的工作負載,token 是新的大宗商品,推理性能直接決定收入
- AI 工廠時代:資料中心已從文件儲存設施演變為token 生產工廠,未來每家公司都將以”AI 工廠效率”來衡量自身競爭力
- OpenClaw 智能體革命:OpenClaw 開啟了智能體運算時代,企業IT 正從工具時代走向智能體時代,每家企業都需要製定OpenClaw 策略
- 實體AI 與機器人:具身智慧正在規模化落地,自動駕駛、工業機器人、人形機器人共同構成實體AI 的下一個重大機會
感謝大家,GTC 愉快!
Source
您可能也會喜歡

川普再度施壓聯準會:小學生都知道現在該降息!市場仍預期本週按兵不動

比特幣攻上 7.6 萬美元、美伊戰火中超越黃金、石油的敘事邏輯是什麼?
